|
|
|
| Retrieval-Augmented Generation (RAG)-Driven Knowledge Service: Principles, Paradigms, and Evaluation |
| WANG Liang |
| School of Economics and Management, Beijing Institute of Graphic Communication, 102600, Beijing, China |
|
|
|
|
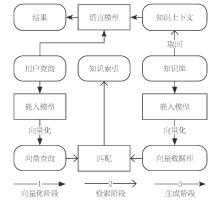
Abstract This paper examines the limitations of artificial general intelligence (AGI) in professional knowledge service domains, particularly its inability to reconcile the breadth of general-purpose corpora with the depth required for specialized expertise, a challenge exacerbated by the static nature of training data and the inherent trade-offs between generalization and precision. These limitations stem from the AGI’s dependence on open-source, nonspecialized training data, which exclude high-value, peer-reviewed resources, and its static architecture, which struggles to adapt to the dynamic evolution of domain knowledge. To address these challenges, this study proposes Retrieval-Augmented Generation (RAG), a hybrid framework that integrates the semantic comprehension and generative fluency of LLMs with the authority and precision of structured knowledge bases. RAG operates through three interconnected phases: vectorization, where domain-specific texts and user queries are transformed into high-dimensional embeddings to capture semantic nuances; retrieval, which employs similarity search algorithms to extract contextually relevant knowledge snippets from vectorized databases, ensuring alignment with professional standards; and generation, where LLMs synthesize retrieved content with user inputs to produce outputs that balance readability with factual accuracy. The implementation of a RAG requires meticulous attention to knowledge base construction, digitization and standardization of domain content through metadata tagging, ontology development, and knowledge graph integration to ensure semantic consistency. Model selection further influences performance: open-source options such as BGE offer flexibility for niche domains but may lack scalability, whereas commercial solutions such as Aliyun’s text embedding provide robust multilingual support at higher costs. LLM selection must align with application needs: models such as DeepSeek-V3 excel in Chinese-language contexts because of localized optimization, whereas GPT-4 proves advantageous for multilingual tasks despite privacy concerns. Experimental validation via simulated datasets—professional technical manuals, educational quizzes, and popular biographies—demonstrated RAG’s efficacy. In professional scenarios, the RAG algorithm achieves excellent accuracy by leveraging structured knowledge bases. However, in educational and popular contexts, accuracy has decreased slightly, but it is still acceptable. For the publishing industry, a RAG offers transformative potential but demands strategic adaptations. Infrastructure localization is paramount for safeguarding proprietary content; hybrid cloud architectures can balance cost efficiency with data security, whereas blockchain integration ensures immutable copyright tracking. Workflow optimization should automate metadata tagging during editorial processes and integrate consistency checks into proofreading stages, reducing manual labor. Data standardization must address multimodal challenges—e.g., aligning image annotations with textual descriptions—to support emerging applications such as interactive textbooks. Copyright protection requires granular access controls and encryption, particularly for subscription-based services. Despite these advancements, the RAG algorithm faces unresolved challenges: multimodal data integration remains computationally intensive, real-time updates strain system latency, and conflicting knowledge sources necessitate advanced conflict-resolution frameworks. Future research should explore adaptive retrieval algorithms, federated learning for decentralized knowledge bases, and hybrid human-AI validation mechanisms to increase reliability. By bridging AGI’s generative capabilities with domain expertise, the RAG not only elevates the precision and adaptability of knowledge services but also catalyzes innovation in digital publishing, enabling industries to harness their authoritative content as dynamic, interactive assets in an increasingly data-driven world.
|
|
Published: 30 April 2025
|
|
|
|
|
|
|
|
|
|

| 大语言模型LLMs | 准确率Accuracy | 精确率Precision | 召回率Recall | F1Score | | 模拟专业出版物(大模型+知识库) | 通义千问-Max-Latest | 0.96 | 1 | 0.9 259 | 0.9 615 | | 通义千问-Turbo-Latest | 0.906 | 0.924 | 0.8 919 | 0.9 077 | | DeepSeek-V3 | 0.918 | 1 | 0.8 591 | 0.9 242 | | 模拟教育出版物(大模型+知识库) | 通义千问-Max-Latest | 0.918 | 0.88 | 0.9 524 | 0.9 148 | | 通义千问-Turbo-Latest | 0.87 | 0.88 | 0.8 627 | 0.8 713 | | DeepSeek-V3 | 0.84 | 0.808 | 0.8 632 | 0.8 347 | | 模拟大众出版物(大模型+知识库) | 通义千问-Max-Latest | 0.894 | 0.96 | 0.8 481 | 0.9 006 | | 通义千问-Turbo-Latest | 0.912 | 1 | 0.8 503 | 0.9 191 | | DeepSeek-V3 | 0.938 | 1 | 0.8 897 | 0.9 416 | | 模拟专业出版物(仅知识库) | 通义千问-Max-Latest | 0.96 | 1 | 0.9 259 | 0.9 615 | | 通义千问-Turbo-Latest | 0.892 | 1 | 0.8 224 | 0.9 025 | | DeepSeek-V3 | 0.918 | 1 | 0.8 591 | 0.9 242 | | 模拟教育出版物(仅知识库) | 通义千问-Max-Latest | 0.92 | 0.88 | 0.9 565 | 0.9 167 | | 通义千问-Turbo-Latest | 0.862 | 0.852 | 0.8 694 | 0.8 606 | | DeepSeek-V3 | 0.89 | 0.82 | 0.9 535 | 0.8 817 | | 模拟大众出版物(仅知识库) | 通义千问-Max-Latest | 0.914 | 0.96 | 0.8 791 | 0.9 178 | | 通义千问-Turbo-Latest | 0.916 | 1 | 0.8 562 | 0.9 225 | | DeepSeek-V3 | 0.96 | 1 | 0.9 259 | 0.9 615 |
|
|
|
| 1 |
国务院关于印发新一代人工智能发展规划的通知[EB/OL]. [2025-02-08]. https://www.gov.cn/zhengce/content/2017-07/20/content_5211996.htm.
|
| 2 |
贾同兴. 人工智能与情报检索[M]. 北京: 北京图书馆出版社, 1997: 15- 103.
|
| 3 |
文森, 钱力, 胡懋地, 等. 基于大语言模型的问答技术研究进展综述[J]. 数据分析与知识发现, 2024, 8 (6): 16- 29.
|
| 4 |
张新新, 丁靖佳. 生成式智能出版的技术原理与流程革新[J]. 图书情报知识, 2023, 40 (5): 68- 76.
|
| 5 |
Medec:a benchmark for medical error detection and correction in clinical notes[EB/OL].[2025-02-08]. https://arxiv.org/abs/2412.19260.
|
| 6 |
朱飞, 张煦尧, 刘成林. 类别增量学习研究进展和性能评价[J]. 自动化学报, 2023, 49 (3): 635- 660.
|
| 7 |
易龙. 从数字出版到智能出版:知识封装方式的演进[J]. 出版科学, 2023, 31 (1): 81- 90.
|
| 8 |
崔浩男. 多模态档案知识服务平台的基本特征与价值取向:基于国内外20个案例的分析[J]. 档案学通讯, 2024 (1): 70- 78.
|
| 9 |
新一代通用向量模型BGE-M3:一站式支持多语言、长文本和多种检索方式[EB/OL]. [2025-02-08]. https://hub.baai.ac.cn/view/34816.
|
| 10 |
阿里云计算有限公司. Embedding模型[EB/OL]. [2025-02-12]. https://help.aliyun.com/zh/model-studio/user-guide/embedding.
|
| 11 |
OpenAI. 嵌入指南(Embeddings Guide)[EB/OL].[2025-02-12]. https://www.openaidoc.com.cn/docs/guides/embeddings.
|
| 12 |
CSDN. 机器学习:回归模型和分类模型的评估方法介绍[EB/OL]. [2025-02-12]. https://blog.csdn.net/rubyw/article/details/142828639.
|
|
|
|