

被引量是指一篇论文出版以来的被引用次数,是人们对论文发表以后的评议,人们对论文关注高,被引次数就高[1]。因此,被引量广泛用于评估论文、专利、期刊、专著、科学家、研究团队、科研机构等的科学贡献或价值[2]。
在当前知识爆炸的时代,研究人员可以方便地获得在某个特定研究领域中的大量论文。对于已经发表超过5年的论文,可以很容易地通过每篇论文的被引情况等评估其影响力。然而,对于只出版一两年的论文,通常覆盖当前研究热点和趋势,却很难预测它们未来的影响。较早地发现具有高被引潜力的论文,将有助于科研人员尽早关注有影响力的研究方向、把握学科发展动向[3]。基于此,预测期刊论文的被引量具有重要的研究意义。已有研究表明,高质量论文在发表后五年内具有较强的知识扩散能力[4],这意味着,一篇论文发表后五年的被引量是论文影响力的重要表现。因此,本研究通过预测期刊论文发表后五年内的被引量来反映论文影响力。
许多学者对期刊论文被引量的影响因素进行了研究。如Robson和Mousques[5]在研究论文被引量影响因素时考虑了页码数、作者数量、参考文献数量、摘要长度、地理位置、学科等指标,发现论文长度即页码数以及参考文献数量是最重要的影响因素;Borsuk和Budden等学者[6]利用广义线性模型(GLM)估算了第一作者的性别、论文语言和作者数量对被引量的影响,发现作者数量具有较大的影响,但是第一作者的性别和论文语言的影响不显著;袭继红[7]、邱均平[8]等学者研究了国际合作或科研合作对论文被引量的影响,发现科研合作在提高平均被引量方面发挥了重要作用。
在图情领域,也有许多关于期刊影响力和论文被引量预测的研究。如王烁、李铁铮[9]以农业经济类的26种期刊为研究对象,选取18项指标,通过因子分析法构建了农业经济类期刊的影响力综合评价模型;Saeed等人[10]运用线性回归的方法对WWW会议论文进行被引量排名预测;Yu等人[11]用回归方法预测了图书情报领域文章的被引频次,并创新性地引入Eigenfactor、Article Influence Score这两项期刊评价指标;鲍玉芳、马建霞[3]将影响论文引用的相关因素按作者因素、文章因素、期刊因素、网络计量学、其他因素这5个维度进行梳理,然后总结了常用的引用预测方法。本文拟通过构建论文特征空间提出影响论文被引量的多维特征指标,运用多元线性模型预测论文的被引量。
相关分析(correlation analysis)是研究现象之间是否存在某种依存关系,测度各变量之间关系密切程度的一种统计方法,它用一个指标数值表示变量之间关系的密切程度。可以按照关系变化的形态分为线性相关分析和非线性相关分析。本文利用的是线性相关分析。
回归分析(regression analysis)是分析具有相互联系的对象,是根据其关系形态,选择一个合适的数学模型,用来近似地表达自变量和因变量间关系的分析方法。本文对图情领域期刊论文的被引量预测,就是通过对期刊论文的特征指标进行分析,建立回归模型,找出论文特征和被引量的准确联系,从而预测在未来一个时期图情领域期刊论文的被引量。然而在影响因素较多的情况下,这些影响因素之间可能存在高度依赖性,会使得所求的回归系数不合理、不科学。针对上述问题,我们采用逐步回归分析。逐步回归分析包括向前选择、向后淘汰和双向消除,在本文研究中,选择双向消除的方法以获得最佳模型。本文使用SPSS的数据统计分析功能,运用SPSS统计分析过程中的相关分析以及回归分析,对影响指标进行筛选并构建回归模型。
笔者首先选取了 "中国社会科学引文索引" (CSSCI)中的图书馆、情报与文献学学科领域的20种核心期刊,由于《情报学报》没有被中国知网(CNKI)收录,故选取除《情报学报》以外的19种期刊作为研究对象。每种期刊按顺序选取自2011年第1期开始的20篇论文,共得到380篇论文作为统计分析样本,利用CNKI提供的高级检索功能,分别统计出各个指标。为便于同时进行模型构建和模型验证,选取其中的320篇论文作为分析样本,其余60篇为测试样本。
考虑数据的可获得性,通过构建论文的特征空间选取相应的指标,描述科学论文的特征大致分为4种类型:论文的外部特征、作者特征、引用特征和出版期刊特征。科学论文的特征空间
其中
论文的外部特征包括文章类型、语言、出版日期、参考文献的数量、论文长度等。为了方便比较,我们只选择参考文献数量作为其中一个变量。根据马太效应,作者的声誉和期刊的知名度可能会影响论文被引量,人们普遍认为,权威学者和核心期刊的论文会吸引更多的关注。用于描述期刊特征的一系列期刊评价指标是从《中国科技期刊引证报告》中选取的。此外,引用特征,如首次被引年限和论文发表后最近两年内的被引量,反映出发表后两年内知识扩散的能力,可用来反映期刊论文的质量。
表1列出了期刊论文的特征。这些特征被广泛接受且易于访问。本研究中,引入首次被引年限的倒数。原因是,一些论文在知网中从未被引用过。首次被引年限的倒数在0到1之间,首次被引年限倒数值越大,论文会在科学界扩散地更迅速。
多元回归分析不仅能提取隐藏在巨大数据集的重要信息,还可以使用变量来预测和控制一个特定的变量。因此,在回归分析中,论文被引量是因变量,表1所示的12个特征是自变量。使用皮尔森相关系数来分析论文被引量
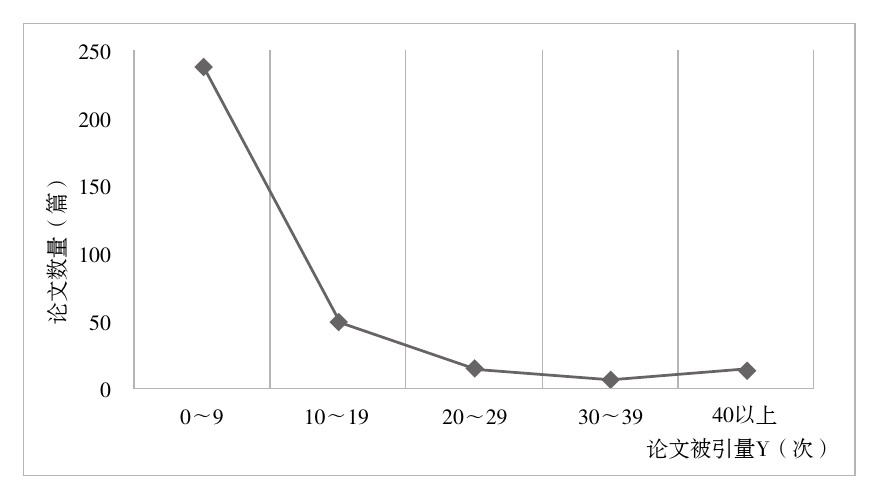
320篇论文的累计被引量是2 852次。图1显示出320篇论文的被引量
总的来说,320篇统计样本中,超过73%的论文参考文献数量在5~20之间,大多数高被引论文都出自北京、武汉、广州、南京等发达地区或著名高校和机构。约82%的论文是由1~2作者完成的,第一作者h指数不超过3的约占20%,第一作者发表论文数量超过10篇的约占75%,第一作者发表论文总被引量不低于30的约占67%,这意味着该领域研究人员大多具有良好的声誉。此外,约74%的论文首次被引年限在发表后两年内,但论文发表后两年内被引量不低于10的仅占约6.5%,这说明论文的引用需要周期,最新发表的论文不能马上体现其影响力。
表2给出了论文被引量与论文外部特征之间的相关关系,发现参考文献数量几乎不会对论文被引量产生作用。这与外国学者的研究结果有差异,原因可能是,选取的数据库不同,中国该领域核心期刊一般对论文的格式、字数、参考文献数量等有严格的要求,且不同的期刊要求略有不同。
表3显示了论文被引量和作者特征之间的皮尔森相关系数。结果表明,作者特征的5个指标与论文被引量有显著的相关性,但相关系数不高。尤其是作者数量
表4显示了论文被引量和引用特征之间的相关性矩阵。结果表明,引用特征是论文被引量重要的影响因素,最近两年的被引次数
表5揭示了论文被引量与期刊特征之间的关系,相关系数接近约0.3,这表明论文被引量和出版期刊特征的相关性高于和外部特征的相关性。论文被引量和期刊总被引频次
我们已经获得了320篇论文的特征分布,并分析了论文被引量和12个特征之间的相关性,然而这些关系并不是特别精确和具体,因此,我们可以利用线性回归模型来解释论文被引量和12个特征之间更准确的关系。
当有多个自变量时,使用逐步回归分析不仅可以保证所选变量的有效性和重要性,而且减少了额外冗余变量所引入的误差。在本文的研究中,由于有多个影响指标,采用逐步回归法可以有效地将对论文被引量这个因变量贡献大的自变量找出来,将贡献不显著的指标自变量剔除,即通过双向消除逐步回归分析,得到如下的回归模型:
对逐步回归分析的结果评判:复相关系数
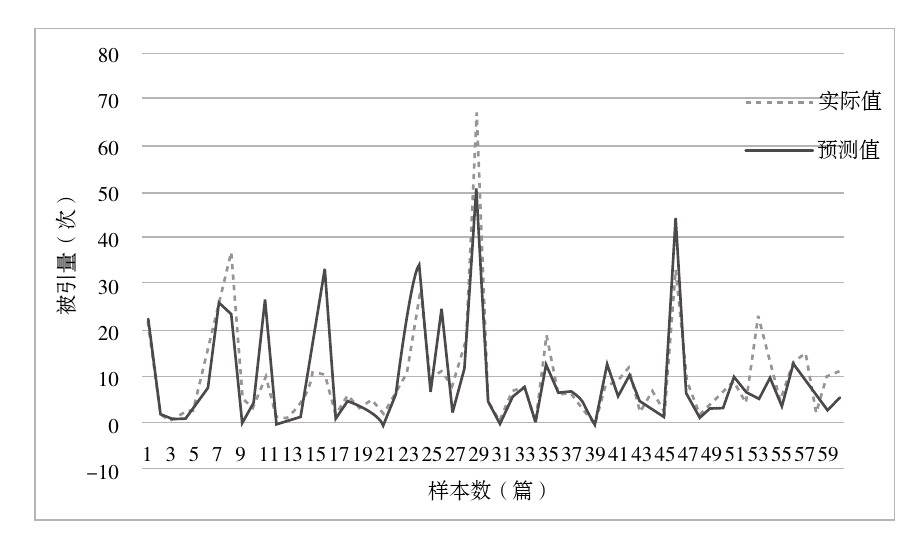
以其余的60篇作为测试样本,比较测试样本的实际论文被引量和回归模型预测的结果,如图2所示,虽然线性回归模型的预测有些误差,但是所预测的结果还是比较客观的,证明了回归模型是有效的。
对于图2中几个预测值远高于实际值的情况,可能有以下几种原因:一是高被引作者或权威专家的文章不是每一篇都具有很高的影响力;二是在2011年之前大量发文的作者近几年科研成果减少,作者影响力下降;三是其他相关领域(如计算机、医学、管理学领域等)的权威作者在图情领域的被引量较少。而预测值低于实际值的情况,主要集中在在校研究生和因为工作需要在某一时期集中发表了一两篇文章,作者声誉及发文量不高,但文章质量较高。
研究结果表明,一篇论文客观的科学计量指标可以预测论文被引量。论文的外部特征、作者特征、引用特征和出版期刊特征都是参与构建论文特征空间的要素。考虑到这些特征所提供的信息可能是冗余的,应用逐步回归分析的方法,从所有的特征中选择有代表性的变量建立模型,用来描述论文特征和论文被引量之间的关系。
期刊论文具有多维复杂的特征,我们的研究中只选择了相对简单和便于获得的特征,这些特征不能直接决定论文被引量,只是重要的影响因素。此外,本文研究的2011年的19个期刊的300多篇论文,样本数量有限,也会造成结果的误差。而且,我们的模型只适用于本文研究的主题领域。接下来的研究将选择更大、更全面的数据,并进一步考虑这些特征的全面性和有效性,比如涉及论文本身、开放存取状态、读者的可接受水平等许多方面。

{kind=link}
{kind=link}
{kind=link}
{kind=link}