

在2017年百度教育论坛上,张亚勤博士提到了ABC对于出版的影响,并明确提出了百度教育事业部“AI+教育”及“AI+出版”的发展规划。ABC,分别为artificial intelligence(人工智能)、big data(大数据)和cloud(云)。无论是叫“互联网+出版”,还是叫“出版+互联网”,云(C)和出版的结合已经被出版人所认同,并在努力践行。大数据(B)和出版的结合现在已经火热,本文将“大数据+出版”和“出版+大数据”定义为两个不同的概念:大数据出版为在行业大数据基础上的出版和服务,是一种狭义的知识服务;出版大数据,为出版业的数据。人工智能(A)和出版的结合,目前有一些应用,但肯定是未来新兴出版的主要方向,需要出版业从业者的不断探索。
随着ABC技术的不断发展,一方面,科技对传统出版的冲击会越来越大,新兴的信息传播方式对传统出版是补充还是颠覆的话题一定会继续很多年;另一方面,作为传统出版人,也应该看到科技对传统出版的推动作用,尤其是大数据和云服务对拉近出版社、作者和读者之间的距离,提升出版社对作者及读者的服务提供了非常好的机遇。本文将以“面向出版行业的定制化数字出版系统研发与应用”(2016年北京科委项目)为例,阐述出版业的数据如何更好地服务于用户。
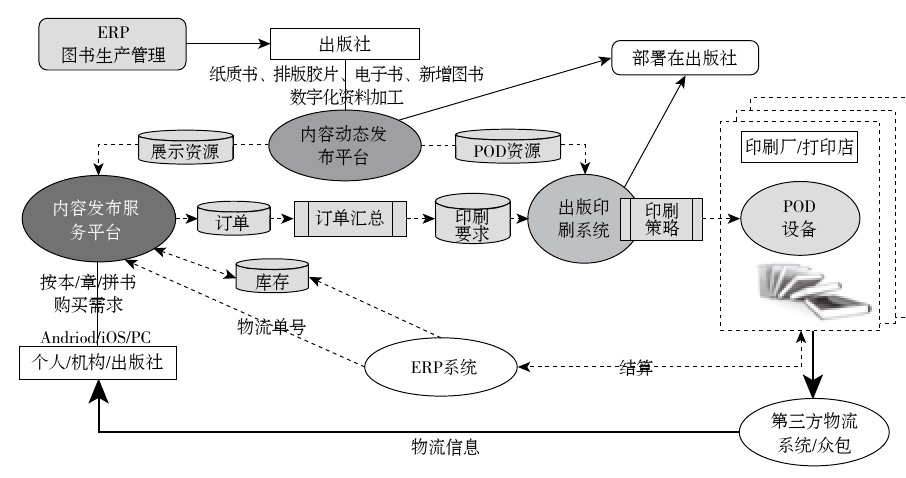
“面向出版行业的定制化数字出版系统”(下文简称POD系统)是清华大学出版社等5家单位联合在北京市科委立项开发的一个按需出版系统,其整体流程如图1所示。
整个系统由3大板块构成,包括内容动态发布平台、内容发布服务平台和出版印刷系统。
(1)内容动态发布平台主要是对出版社的图书数字资源进行存储和管理。
(2)内容发布服务平台是图书电商平台及各类在线服务平台。用户可在内容发布服务平台购买图书(包括断版书),用户提交订单后,内容发布服务平台会将订单推送给出版印刷系统;用户可以购买电子版,进行在线阅读;用户可以在各类在线知识服务平台上进行搜索、学习等,也可将自己收藏的学习资料提交给出版印刷系统进行打印。
(3)出版印刷系统接收到订单后,生成印制单,将印制单和图书数字资源推送给印刷厂,印刷厂接收到这些信息后开始印制图书并发货。
用户收到图书后,通过内容发布服务平台进行收货确认;同时和电子版阅读一样,可以进行图书评价,分享阅读心得,并与作者进行互动。
从用户范围的角度,系统内的数据主要围绕出版社、读者和作者而产生。出版者、作者和读者既是数据的生产者,又是数据的使用者,也是出版数据最后要服务的对象。
从出版社的角度来看,出版数据可以分为内部数据和外部数据。内部数据是出版社日常生产活动中产生的各类数据,存在于出版社ERP、客户关系管理系统、资源管理系统等内部业务系统之中,包括作者数据、图书数据、图书销售数据、大客户数据、各类数字资源等。外部数据指出版社日常生产活动中难以收集的数据,获取渠道有电商平台、第三方数据公司等,包括读者数据、详细销售数据等。
在POD系统内,对出版数据的处理流程可分为4个步骤,如图2所示。
数据采集指收集出版业原始数据的过程。数据来源包括出版社ERP、电商网站、第三方数据公司、线下数字化资源等。
数据清洗的过程是指对数据进行一些处理,过滤无用的信息,规范得到能进一步分析利用的数据。包括但不限于以下情况:
(1)过滤垃圾数据,例如被攻击/造假/BUG产生的大量数据;
(2)抽取有用字段,上传的数据包含的信息有很多,我们只用到一小部分;
(3)原始数据有很多格式不规范或不统一,要规范和统一数据格式。
对清洗环节的数据进行补充和预处理,便于数据建模分析使用。采集、过滤后的数据有些并不能够直接使用,还需要补充一些信息,如数字化资源的标引数据、基于用户行为的数据整合数据、独立的用户行为跟踪数据、事件标签化数据等。
数据模型是整个数据处理分析的核心。出版单位应该根据自己的核心业务和数据,结合自身的发展目标建立数据模型。
以数据模型构建用户画像为例:可以根据不同用户产生的各类数据为用户添加标签,如某用户购买婴儿早教类的图书,可以给他打上年轻父母的标签;如果能够根据图书的适龄人群推断出孩子的年龄,系统就能在之后的几年里根据不同学龄阅读需求为该用户推送儿童读物和教材;再比如,某读者购买了JAVA编程类的图书,那他可能是个JAVA程序员,可以给他推送JAVA或算法类的书籍。出版社获取到的用户数据越多,构建的用户画像就越精确,就能提供更好的个性化服务。
用户画像通过加标签的方式把庞杂的用户群具象化,使出版社有可能为每个读者推送个性化的服务;将具有相同标签的用户划分成一个个群组,就能针对不同人群做垂直服务。
在经过数据采集、数据清洗、数据加工、数据建模分析等步骤后,我们可以得到结构化数据。把数据应用于出版社平时的生产经营中,构建大数据驱动的新型生产经营模式,是传统出版社升级转型的一条思路。
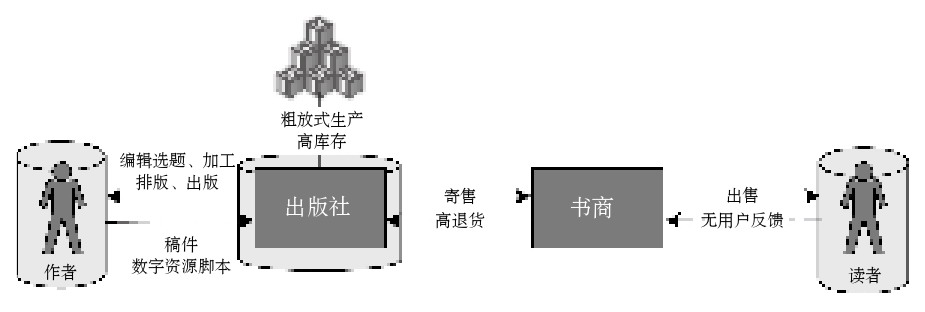
传统出版业中的数据是一个个的信息孤岛,读者、作者、出版社之间数据闭塞,作者接触不到读者的阅读反馈,出版社接触不到有效的市场信息,出版社大量的数字资源也得不到有效利用,如图3所示。信息闭塞会带来各种问题,如编辑选题缺乏数据支持、粗放式生产、高库存、高退货率等,在生产经营中造成重大损失。
数据整合是要将出版业数据有效地整合、统一起来,通过整理分析,为用户提供各类数据服务,可以有效增加出版社生产经营效率,并为出版社的转型升级提供数据支持。
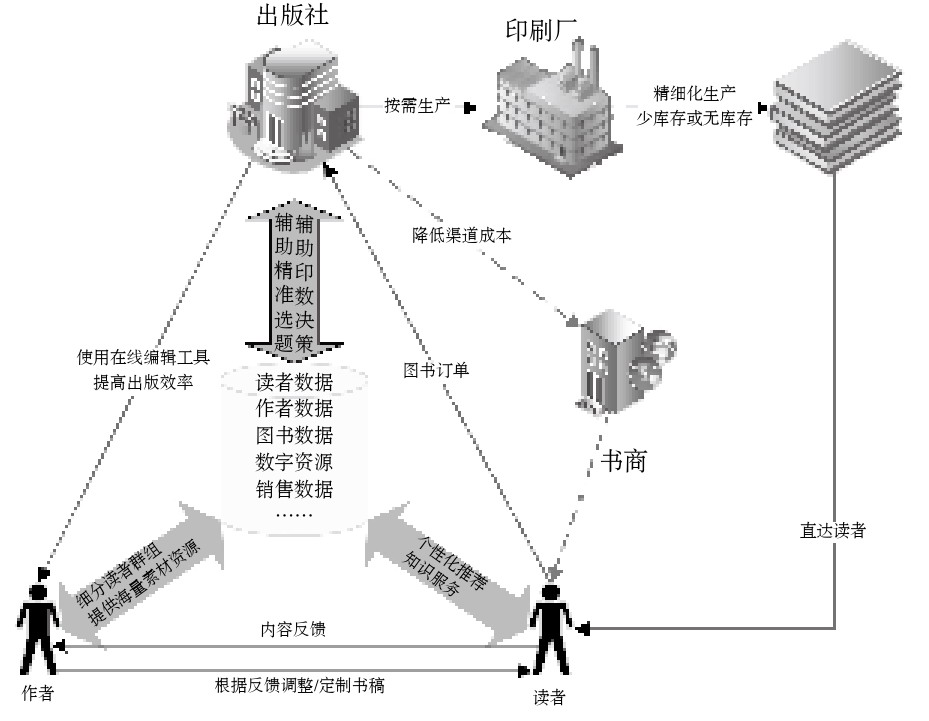
图4所示为POD系统设计中所采用的大数据驱动的新型生产经营模式。这种生产经营模式的核心就是数据整合,通过对数据的整合,使出版社掌握用户的行为数据和阅读数据,在生产经营中提供相关数据服务。
(1)主要数据服务。面向出版社:辅助精准选题、辅助印数决策;面向作者:细分读者群组、提供海量素材资源用于内容创作;面向读者:个性化推荐、知识服务。
(2)经营效益提升。图书按需生产、少库存或无库存;直达读者,不经过书商,降低渠道成本;使用在线编辑工具,提高出版效率。
选择出版社、作者、读者三类出版业主要用户,通过具体案例,从断版书销售、内容创作、个性化推荐三方面展开介绍大数据驱动下的新型生产经营模式。
(1)服务出版社:断版书销售。
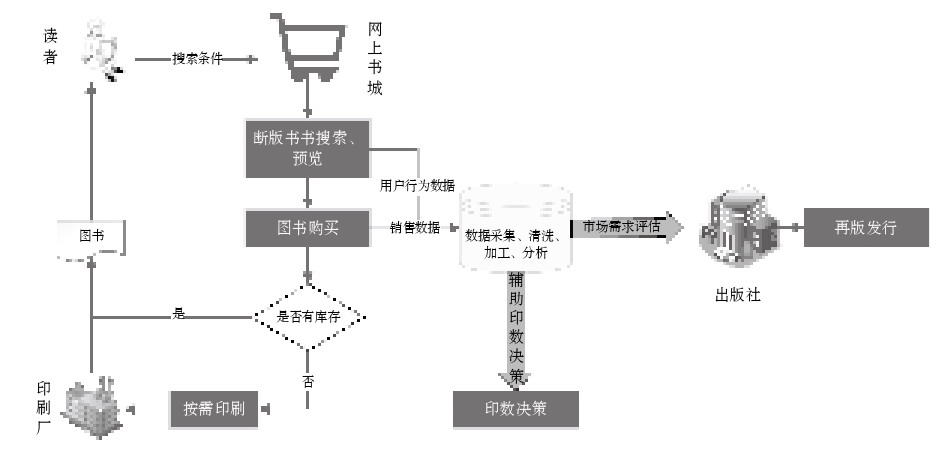
传统出版社断版书销售面临两大问题:一是市场需求难以评估,导致大量断版书订单流失;二是对于需求量大的断版书,再版发行阶段印数决策缺少数据支持,主要靠编辑经验决定印数,容易造成高库存。
POD系统通过采集终端读者的行为数据和商城销售等数据,通过数据处理分析,为出版社提供断版书市场需求评估服务,并在再版发行阶段辅助编辑进行印数决策,见图5。
数据驱动下的断版书销售主要解决了出版社零散订单流失问题,做到按订单生产、按需印刷。另外,在数据分析的辅助的印数决策,能够在一定程度上预判市场需求,在现有订单上增加以后半年的需求量,统一印刷,有效降低数字印刷成本。
(2)服务作者:基于读者反馈的内容创作。
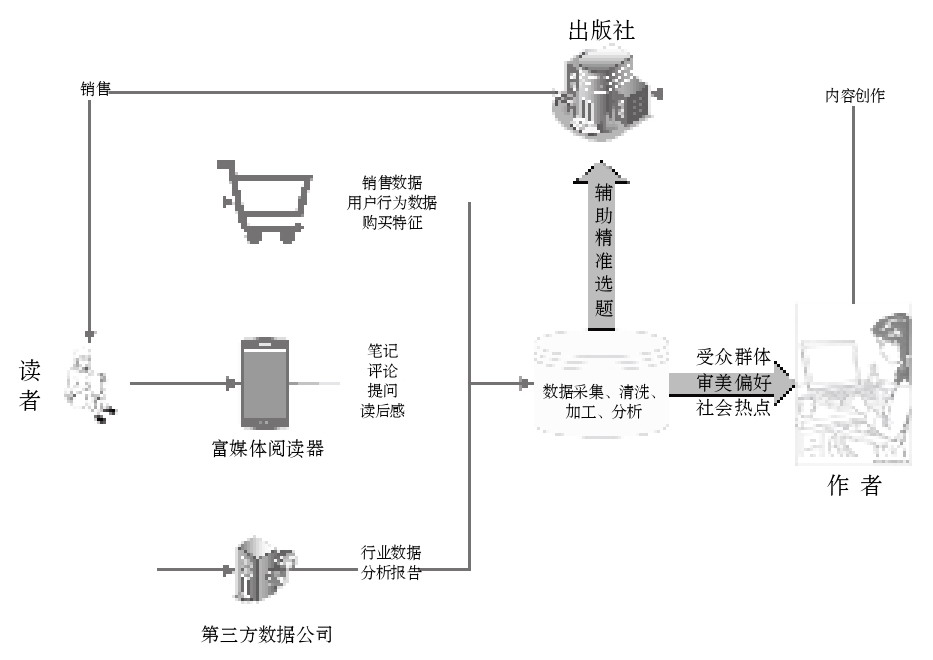
基于读者反馈的内容创作是POD系统提供给作者的一项数据服务。主要是通过对读者反馈数据的分析,抽提用户读书特征,对读者的知识图谱进行画像,向作者提供其受众群体的知识层次、感兴趣的领域、审美偏好等信息,帮助作者进行内容创作,见图6。
读者反馈数据主要有三个来源,一是POD电商平台的各类图书销售数据和运营中采集的用户行为数据;二是读者在POD富媒体阅读器中产生的笔记、评论、提问、读后感等内容;三是来自于第三方数据公司的行业数据和分析报告。
(3)服务读者:基于用户画像的个性化推荐。
“基于用户画像的个性化推荐”通过对数据建模分析,建立起用户和内容的关联关系,为每个用户提供个性化的图书推荐服务。
如图7所示,POD系统中“基于用户画像的个性化推荐”服务主要由三个步骤实现:首先,对用户和内容特征化,构建用户和内容的标签库;其次,使用LFM模型(Latent factor model,隐因子模型)对标签库处理,实现用户和内容的分类;再者,运用基于模型的协同过滤算法对每个用户进行个性化推荐。
个性化推荐服务简化了用户的购买操作,节约用户的时间,能够有效提高用户从浏览者到购买者的转化率,从而增加出版社的营收。另外,精准的推荐服务会使用户对系统产生依赖,使出版社与用户建立长期稳定的关系,从而有效保留用户,提高读者的忠诚度,防止用户流失。
出版业的数据如何推动传统出版,如何更好地服务于读者,需要出版从业者不断探索,长期实践。我们认为把数据应用于出版社平时的生产经营中,构建大数据驱动的新型生产经营模式,是传统出版社升级转型的一条思路。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}