1 问题的提出
随着人工智能生成内容技术(artificial intelligence generated content,以下简称AIGC)的迅速崛起,人类似乎正式开启了全面通往“数字时代”的新征程。AIGC是指利用人工智能技术进行文字、图像、视频、音频、游戏等内容的自动化输出;而ChatGPT就是一个基于GPT-3.5架构的大型语言模型,其技术路线是通过使用神经网络和自然语言处理技术,形成强大的语言理解和生成能力。ChatGPT的出现大幅度提升了AIGC技术的生成效率与输出语言内容的丰富度,并被广泛部署于对话交互、文本写作、文本翻译等应用场景;可以说,ChatGPT是实现AIGC技术突破的重要标志。既然以ChatGPT为代表的AIGC新技术已使人工智能实现了如此强大的智能水平和创作能力,那么人工智能生成内容是否能够受到版权意义上的保护?在以往研究中,已有不少关于人工智能生成内容可版权性问题的学术探讨,但这些学术成果多是对传统人工智能生成技术进行的回应。[1 ,2 ,3 ,4 ] 与传统技术相比,ChatGPT等大语言模型人工智能在文字理解力、文本处理量、文本输出速度等方面均取得了飞跃性进步,其强大的技术优势也催生了该行业新的运营模式和发展进路。因此,笔者将以ChatGPT生成内容为例,结合AIGC新技术的发展现状和行业特点,尝试对人工智能生成内容的可版权性问题进行回应。
2 赋予版权的理论契合度不高
在著作权理论构建中,黑格尔的“人格价值论”有力证明了这一制度设计的正当性。作者权体系的立法传统认为,作品应当具备“独创性”,即应当反映作者的“个性”,或传递作者的“思想、情感等”[5 ] ;作品是“人类创造力”的集中体现。[6 ] 由于人工智能技术的快速迭代,有学者认为,人工智能的生成过程已不再是机械地“创作”,而是在没有预设算法或者规则的情况下,通过机器的主动学习来进行“创作”,著作权法的保护应延伸到人工智能的创造内容。[7 ] 然而,笔者认为,即便是ChatGPT这样先进的人工智能,其“创作过程”仍是以“算法”为本源、以“数字”为基础的,对表现作者“个性”力所不及。
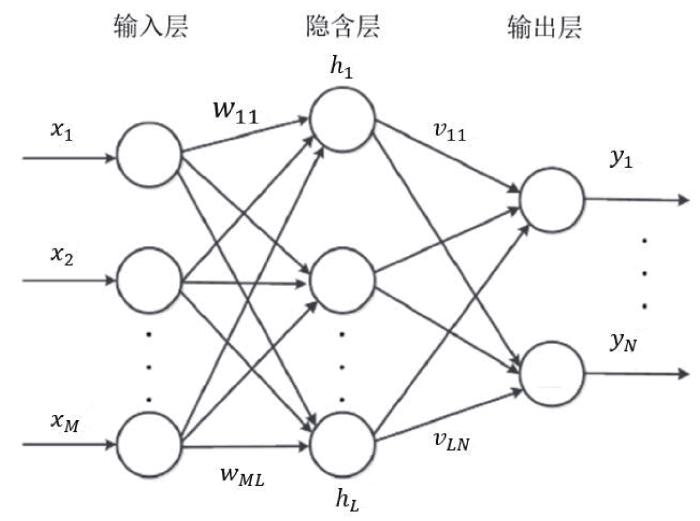
不可否认,如今的人工智能生成内容在表现形式上已与人类作品几无差别。与使用普通算法的传统软件不同,以ChatGPT为代表的生成式人工智能(generative artificial intelligence)往往需要训练并创建不同类型的神经网络算法。神经网络的基本原理是运用大量简单的组件搭建一个灵活的“计算结构”,并让这个“结构”能够被逐步修改,以便从经验数据中充分学习。神经网络的实际学习过程,简言之,是以确定权重(或概率)的方式较好地“捕捉”输入值(见图1 )。[8 ] 此外,从目前神经网络的设置来看,ChatGPT等生成式人工智能的底层逻辑都是建立于数字之上;因此,当我们运用ChatGPT等生成式人工智能来处理文字、图像等素材时,仍需要将素材内容分配或转化成数字。[9 ]
图1
图1
神经网络结构简化表征图
x 为输入值矩阵,y 为输出值矩阵,h 为隐含层的非线性函数(即激活函数),w 与v 分别为神经网络输入、输出权值矩阵。
基于神经网络结构的搭建,以ChatGPT为代表的生成式人工智能不再像传统软件那样死板,“它运行的逻辑不是基于经典函数 f =X →Y ,而是类似于概率函数kernelμ:X →Pr( Y );即输入是从一个概率分布μx f(x) 附近”。[10 ] 一方面,ChatGPT更为灵活,更擅长处理一些嘈杂无序的输入值;另一方面,ChatGPT的“生成思维”也更为发散,其输出并非某一确定值,而是随机的,输出值落在完美结果的附近。
除此之外,其他算法(如RLHF基于人类反馈的强化学习)、数据(1 750亿个模型参数)、算力等方面的技术突破也令ChatGPT的智能化程度越来越高。但当涉及ChatGPT能否在生成内容中表达作者“个性”的疑问时,其答案仍应是否定的——原因在于ChatGPT虽然显现了较强的人工智能属性(未达到全能),但尚不具备创作意图,其创作过程缺乏认识要素与意志要素。例如,在对ChatGPT进行自然语言训练时,ChatGPT会发现“草莓”和“蓝莓”在同类语句中经常相互替换,两者具有“相似性”;但这种相似是ChatGPT从大量语句中通过概率计算得出的,其并不能以感性直观了解到两者具有“味甜”“解渴”等共性。即便通过大量训练发现“草莓”“蓝莓”与“味甜”“解渴”常出现在同一语句,但如何才是“甜的”“解渴的”,ChatGPT根本无从感受。因此,ChatGPT不以感性直观为基础的“认识”并不能成为真正的认识。
另外,ChatGPT的创作过程同样缺乏意志要素,即创作的主动性——在作品当中主动融入自己的情致、性格、偏好等——其往往需要借助创作者的灵感与想象力。黑格尔在《美学》中指出:“‘情致’是艺术创作的真正中心和适当领域。对于作品和观众来说,情致的表现是效果的主要来源。”[11 ] 因此,创作一方面要反映客观对象的某些属性和特征,另一方面也要加入主体情感等个性色彩。[12 ] 以计算为本位的ChatGPT,既不具备表达个性的情致等条件,也缺乏在事物之间创造联系的无拘无束的想象力。可以说,ChatGPT的内容生成是建立在人类既有经验素材基础上的,其本身缺乏能力来拓展创作与想象的边界。从这一视角来看,ChatGPT生成内容具有不同程度的“同质性”,并非著作权所保护的目标对象。[13 ]
3 赋予版权的实践可行性欠缺
3.1 向人工智能创造者(或投资者)赋权的视角
3.1.1 赋权并不必然带来收益的利好
部分学者认为,赋予创造者(或投资者)人工智能生成内容的版权,能够鼓励人工智能的技术创新和产业发展,因为此举可以使人工智能生成内容产生与人类作品同样的版权收益。[14 ,15 ] 持该观点的学者无疑是希望加强创造者(或投资者)对人工智能生成内容的控制力,将人工智能生成内容的社会收益完全内部化,以实现人工智能产业增长的激励效果。
然而在设计激励机制时,无论是财产权还是类财产权保护的知识产权,都并非追求对权利客体的“完全控制”。财产权概念作为“权利束或权利集群”意味着财产利益必然是可以分割的,而如何分割、如何基于需要对相关利益进行取舍,则应当依照具体情况予以定夺。[16 ] 著作权保护客体是十分特殊的信息,而信息的特点在于:一方面,信息的消费具有非竞争性,即一些人对该产品的消费并不减少其他人对该产品的消费,增加消费者的边际成本为零;另一方面,信息的占有具有非排他性,即信息无法在事实上排他占有,没有产权设定则无法在市场中获得该信息的收益。[17 ] 由此可知,信息既需要在流转中实现增值,又需要以产权加以保护;而在信息上设定权利必然会限制信息的再利用——当付费成为使用信息的前提,信息的传播就会受阻。
因此,在人工智能生成内容之上设定权利并非越多越好,我们必须慎思信息类产品外部收益的内部化程度,即收益的内部化应足以补偿相应投资并获取合理利润,但不能过度。以当前ChatGPT的收益模式为例,ChatGPT的运营采用“订阅制”模式:ChatGPT-3.5网页端提供免费服务,GPT-4(ChatGPT Plus)网页端提供20美元/月的收费服务;两版ChatGPT接入应用程序编程接口(application programming interface,以下简称API)的服务均按照客户端向服务端请求数据量(tokens)进行收费(GPT-4此类服务收费更高)。[18 ] “订阅制”服务在价格、选择和灵活性方面都颇具吸引力,大众消费者很容易被征服;如网飞、Hulu等视频网站,Playstation Now、EA Access等在线视频游戏库,以及Photoshop等应用程序软件均通过“订阅制”向客户提供服务,这为公司带来了相对可预测的收入流。[19 ] 可以说,后数字时代的信息传递与保护已呈现出从“产权设定”到“订阅服务”的转型;ChatGPT的运营者OpenAI在商业发展规划上,也战略性地舍弃了将其生成内容版权化的产权收益模式。ChatGPT“用户使用条款”明确写道:“用户可以向服务提供输入(‘输入’),并接收服务根据输入产生和返回的输出(‘输出’),输入和输出统称为‘内容’。在两者之间以及在适用法律允许的范围内,用户拥有所有输入内容;用户如遵守这些使用条款,OpenAI将特此向用户转让其对输出的所有权利、所有权和利益。OpenAI可在必要时使用内容以提供和维护服务、遵守适用的法律和执行我们的政策。用户须对内容负责,包括确保其不违反任何适用法律或这些使用条款。”[20 ] ①
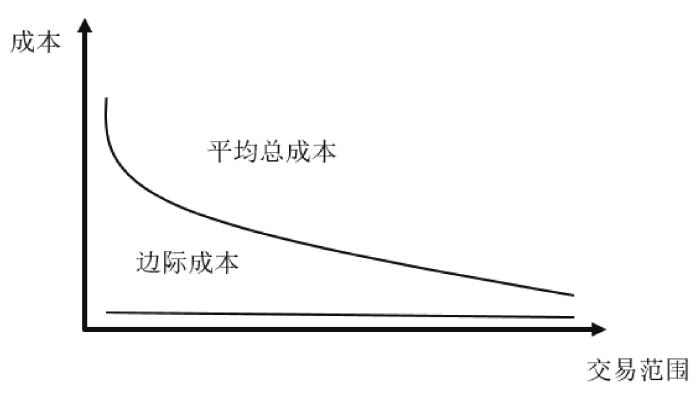
OpenAI这一做法的确经过慎思:首先,通过转让生成内容的权益,让用户对该内容负责,能够在某种程度上规避生成内容可能包含的侵权风险;其次,由于各国法律对人工智能生成内容可版权与否的态度尚不明朗、有无生成内容的版权收益尚不明确,那么选择“订阅制”运营模式将有益于带来更为稳定的收入流。最重要的是,OpenAI绕过“版权”而取道“订阅制”,实际上是实现了部分外部收益的内部化,且随着用户量的不断攀升,可以合理期待相关收益能在未来弥补前期大量的投资成本。值得关注的是,由于此类信息订阅服务的固定成本相当高,而边际成本相对很低,那么其吸纳的用户越多,其平均总成本也就越低;因此,服务提供者完全可以通过扩大交易范围来有效降低平均总成本(见图2 )。[16 ] 倘若在生成内容上设定版权,则很可能导致用户进入门槛的提高与用户数或用户使用量的锐减,与原本期望的收益模式相违背。
图2
除了上文提到的各类收费不菲的订阅服务,ChatGPT还被集成到微软Bing搜索而开创了功能更强的New Bing搜索引擎、被集成到微软Office而成了使用更高效的Microsoft 365 Copilot办公软件;OpenAI甚至推出了ChatGPT Plugins(ChatGPT插件集),通过将ChatGPT连接到第三方应用程序,打造出更为先进的信息交互生态。这些进路一方面将转变为ChatGPT的有效收益渠道,另一方面也同样依赖于大规模的用户数及用户使用量来扩大收益,如此就更加削弱了对ChatGPT生成内容赋权的现实动力。②
3.1.2 权利的救济困难与“权利寻租”的诱发
知识产权法用以维系权利排他性的方法之一是抡起侵权责任的“大棒”。然而在数字信息时代,权利人尽最大努力也很难起诉到每一个下载、复制或传播盗版内容的人;即使能够起诉,其举证难度也颇大,起诉成功的概率很低,权利得到救济的可能性十分有限。[19 ] 同理,倘若给予创造者(或投资者)以人工智能生成内容版权,那么由于服务平台的用户数和用户使用量巨大,将存在数量惊人且分布在世界各地的潜在侵权人;而一些相关网络社群的出现,则很可能使侵权发生得更加容易。由此可见,赋权将会导致维权成本居高不下,权利救济十分困难,甚至权利运行本身难以为继。[17 ]
进一步思考,倘若创造者(或投资者)能够成功起诉部分侵权人获得赔偿,那么一旦这些批量诉讼带来了可观收益,则很可能会吸引创造者(或投资者)转移更多的资源和精力来开展类似的诉讼活动。换言之,由于生成式人工智能的研发消耗极大且研发效果难料,诉讼带来的收益似乎更为稳妥;因此,技术研发的投入成本或被削减,技术创新的激励预期与实际效果之间将出现偏差。
另外,诉讼带来的可观收益将诱发“权利寻租”的产生。“权利寻租”固然会使权利人获益,但该收益“并非是通过生产性活动使社会总体财富增加,而是通过公权力保护实现财富转移”。[13 ] 也就是说,由于人的自利性,对人工智能生成内容赋权很可能造成大量版权资源集中于少数人之手,而这种版权上的“圈地”行为将严重破坏原本平衡的利益生态。另外,“权利寻租”和权利滥用还会导致行政资源和司法资源的巨大浪费,使得知识产权的管理和执行成本不断攀升、司法救济渠道被不当挤占。[21 ] 值得注意的是,相较于人类的创作过程,以ChatGPT为代表的人工智能新技术在生成内容时的速度更快、效率更高且“不眠不休”,那么由此造成的版权“圈地”行为和资源浪费问题也就愈发严峻和棘手。
3.2 向人工智能使用者赋权的视角
知识产权制度的最终目标是促进科技文化事业的繁荣发展,因此要通过赋权为创作者或发明者提供经济上的激励,以使公众受益。但是,由于时代发展下技术条件的变革,ChatGPT等生成式人工智能释放出了新的技术红利,那么该技术红利对激励机制的影响如何,就需要进行重新评估。ChatGPT等生成式人工智能带来的技术影响主要反映在对创作方式和创作生态的改造上:对比过去人类创作时在专业知识和专业技艺方面的较高要求,ChatGPT等生成式人工智能为用户开放的使用门槛要低得多——即使是文学或绘画“门外汉”,也能够用生成式人工智能写出一篇精彩的文字或绘制出一幅出色的画作。
生成式人工智能对创作方式和创作生态的改造将带来以下后果:一方面,随着该技术的成熟与普及,会有海量满足“最低限度的创造性”的作品被源源不断地生产出来,而由于数量之巨大,这些作品的价值会被迅速“摊薄”成为“非稀缺”物品;由于对“非稀缺”物品设定产权是冗余的,那么对生成内容赋权的必要性就随之丧失。[22 ] 另一方面,在资源有限的情况下,激励机制往往倾向于把权利分配给“最有效率”的资源使用者;著作权法的立法动机固然是要保护所有进行独创性表达的作者,但也“青睐”于激励作者中更具创造力和想象力的人——换言之,在创作领域“最有效率”的赋权对象通常是科技文化从业者或相关专业人士,因为他们更有可能基于激励持续创作出高质量的作品。然而,在生成式人工智能的加持下,人工智能使用者们已皆为“作家”或“画家”,市场无法将专业的创作人士区分出来;因此,向人工智能使用者赋权很有可能导致版权的实际赋予者和目标赋予者错位,出现激励偏差。除此之外,将版权赋予使用者,很可能会导致使用者的“创作惰性”,因为既然可以直接依托人工智能生成有版权的作品,那何必自己进行创新?ChatGPT等生成式人工智能最终反而成了“代替”人类进行创新和思考的巨大威胁。
综上所述,放弃向使用者赋权似乎更为可取。放弃赋权意味着将人工智能生成内容视为一个海量的素材库,使用者均可依照自身需要“调取”素材,从而免去了大量烦琐和枯燥的基础性工作;同时,使用者可以在生成内容的基础上形成自己有差异化的作品。向差异化作品赋予版权才更能实现对目标对象的有效激励,更能催生出人类创作者的创造力与创作热情。
4 面向人工智能及其生成内容的因应之道
鼓励创作与信息传播之间的固有矛盾决定了对信息产品的赋权必须谨慎,因为在信息上设定排他性权利往往会与公众对已知信息的正常使用发生冲突;立法者只有对各方利益进行充分权衡,才能为新兴技术与公众生活的良性互动提供稳定预期。对于版权理论中对信息“独占”的强调,学者彼得·德霍斯(Peter Drahos)曾旗帜鲜明地指出,这种“独占”将会严重限制甚至威胁到公众的消极自由。[23 ] 相较于实物性财产,信息具有“公共产品”的特殊属性,可以被不同使用者同时获取,因而在信息上设定权利对公众生活的影响更大;此外,信息的传播与利用涉及诸多基本权利的实现,信息成了人们无法回避的“公共资源”。事实上,法律并不禁止作品之间的模仿,因为任何形式的创作都不可避免会涉及对已知信息的利用;对思想与表达进行“强制”区分的用意更多是据此来设定专有权利的保护范围,人为地制造出受保护客体的“稀缺性”。由于赋权会在保障私人收益的同时增加社会成本,有学者据此认为:“只有在能够使创造者收回平均固定成本的限度内才能给予知识产权,超出这一限度是有害无利的。”[16 ]
对于人工智能生成内容的可版权性问题,我们同样需要设想赋权会给各方利益带来的可能影响:首先,不论是将版权赋予生成式人工智能的创造者、投资者还是其使用者,都将形成数量惊人的版权“壁垒”,从而严重阻碍公众对信息的正常使用,不利于公众福祉的增加;其次,以ChatGPT为例的生成式人工智能的创造者(或投资者)选择了以“订阅制”模式来弥补ChatGPT的前期投资与开发成本,“订阅制”更为稳定的收入流将在很大程度上达成推动行业持续发展的激励效果,而再向其创造者(或投资者)赋权则不免“画蛇添足”,甚至导致“赢者通吃”的失衡局面;再次,“订阅制”的利润增长需要以不断吸纳用户、提升用户使用量为前提,而赋权给创造者(或投资者)将会严重影响这一目标的实现,且“订阅制”已成为包括ChatGPT在内的生成式人工智能软件当前所普遍采用的收费模式,赋权就更需慎重;最后,将版权赋予生成式人工智能的使用者,很可能会导致使用者的“创作惰性”,也会影响市场对专业创作者的甄别,造成预期激励与实际效果之间出现偏差。由此,在各方利益权衡之下,较为明智的选择是使人工智能生成内容回归“公共领域”,将其视为人类进行创作的公共素材资源。
美国版权局于2023年3月发表了一份政策声明,作为生成式人工智能迅速崛起之下其生成内容可版权性问题的首批回应。目前,美国版权局已收到一批包含有人工智能生成内容的作品注册申请,例如,由人类创作者所编写文本和人工智能所生成图像组成的图像小说。美国版权局认为,人类创作者可拥有作品中的文本以及图文编排部分的版权,但作品中由人工智能所生成的图像需要被排除在外;其原因在于“要成为‘作者’的作品,必须由人创造,而该局不会注册由机器或仅仅是随机或自动运行的机械过程所产生的作品,而没有人类作者的任何创造性投入或干预……版权局首先会询问这一作品是否基本上是人类的作品,而计算机(或其他设备)只是一种辅助工具,或者作品中的传统作者要素(文学、艺术、音乐表达或选择、安排等要素)实际上不是由人而是由机器构思和执行的”。[24 ] ① [24 ] ②
因此,对于人类创作者而言,确保作品版权的最佳途径是在人工智能生成的原始素材基础上形成更为“差异化”的内容表达,从而突出自己在创作过程中的“实质参与”。例如,人类创作者可以修改由人工智能生成的原始素材,且修改程度需要达到版权保护所要求的创造性标准;人类创作者也可以筛选、调整并安排人工智能生成的原始素材,其创作贡献应足以使原始素材重构为一个整体性的原创作品。唯有如此,人类创作者才能保证其版权的取得,也才能在海量的作品竞争市场中获得有利的议价地位。
此外,ChatGPT等生成式人工智能的出现,不仅预示着内容创作方式的快速迭代,也使问题与风险随之而来。不可否认,使用生成式人工智能的人类创作者确有可能以人工智能生成内容来充当个人作品,但需要注意的是,抄袭与冒充不仅是人工智能时代的产物,也是一直以来纯粹人类创作时期致力于遏制、改善却始终无法根除的问题;因此,仅仅依靠制度设计来规避上述风险很难说能有所成效。诚然,生成式人工智能的大量应用确有可能使得抄袭问题更为严重,但“对症之举”并非在于生成内容的可版权性与否——因为是否赋予版权都不可避免会出现对人工智能生成内容的冒用现象,那么当务之急就应当是以科技佐之以制度,积极构建与研发人工智能生成内容的识别与区分技术。
5 结语
由ChatGPT等生成式人工智能带来的技术“质变”,已经开始对社会公众的创作习惯、生活方式产生冲击;法律在面对这种技术“质变”时,应当摆脱对传统人类行为习惯的路径依赖,通过不同维度下的理性假设与分析,审慎回应可否向人工智能生成内容赋予版权的疑问。从理论维度来看,“人格价值论”不能有效证明“应当承认人工智能生成内容版权”命题的合理性,该命题与著作权理论间的契合度并不高。从实践维度来看,著作权的目标仅在于维持激励信息生产所需的“最低保护标准”,即收益维持在保证收回投入成本的基础上,因而向已通过“订阅制”获得大量收益的ChatGPT等生成式人工智能创造者(或投资者)赋予版权就显得殊无必要;同时,向创造者(或投资者)赋权很可能导致巨额的维权成本并削弱生成式人工智能技术服务对用户的吸引力,因而创造者(或投资者)本身也缺乏“争取”版权的现实动力。而向生成式人工智能使用者赋权则会影响市场对专业创作者的甄别,造成激励偏差;也会削弱人类创作者的创作动力与创作热情。因此,关于人工智能生成内容可版权性问题,在反复权衡之下,不予赋权才是合理之选。人类历史的演进并非匀速,人类社会也必定会遭受某些新技术的突然冲击。面向以ChatGPT为代表的AIGC技术,人们应当将ChatGPT作为辅助人类进行更好创作的“工具”而非“主体”,回归ChatGPT服务于人类的技术初衷。
① “You may provide input to the Services (‘Input’), and receive output generated and returned by the Services based on the Input (‘Output’). Input and Output are collectively ‘Content.’ As between the parties and to the extent permitted by applicable law, you own all Input, and subject to your compliance with these Terms, OpenAI hereby assigns to you all its right, title and interest in and to Output. OpenAI may use Content as necessary to provide and maintain the Services, comply with applicable law, and enforce our policies. You are responsible for Content, including for ensuring that it does not violate any applicable law or these Terms.”
See Terms of use -3. Content -(a) Your Content (20230309)[20230402] https://openai.com/policies
② 除ChatGPT外,其他已知生成式人工智能的付费模式也多为按月付费或按次付费的“订阅制”(如AI图像生成工具百度文心一格、Stable Diffusion、Midjourney等),可见“订阅制”是当前生成式人工智能的首选收益模式,未来也很可能在生成式人工智能产业中被普遍推广。
① “To qualify as a work of ‘authorship’ a work must be created by a human being and that it will not register works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author…It begins by asking whether the ‘work’ is basically one of human authorship, with the computer (or other device) merely being an assisting instrument, or whether the traditional elements of authorship in the work (literary, artistic, or musical expression or elements of selection, arrangement, etc.) were actually conceived and executed not by man but by a machine.”
See Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence https://www.federalregister.gov/documents/2023/03/16/2023-05321/copyright-registration-guidance-works-containing-material-generated-by-artificial-intelligence
② “For example, when an AI technology receives solely a prompt from a human and produces complex written, visual, or musical works in response, the “traditional elements of authorship” are determined and executed by the technology—not the human user. Based on the Office【-逻*辑*与-】amp;apos;s understanding of the generative AI technologies currently available, users do not exercise ultimate creative control over how such systems interpret prompts and generate material. Instead, these prompts function more like instructions to a commissioned artist—they identify what the prompter wishes to have depicted, but the machine determines how those instructions are implemented in its output.”
See Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence https://www.federalregister.gov/documents/2023/03/16/2023-05321/copyright-registration-guidance-works-containing-material-generated-by-artificial-intelligence
参考文献
View Option
[1]
吴汉东 人工智能生成作品的著作权法之问
[J]. 中外法学 ,2020 ,32 (3 ):653 -673 .
[本文引用: 1]
[2]
李伟民 人工智能智力成果在著作权法的正确定性:与王迁教授商榷
[J]. 东方法学 ,2018 ,63 (3 ):149 -160 .
[本文引用: 1]
[3]
王迁 论人工智能生成的内容在著作权法中的定性
[J]. 法律科学(西北政法大学学报) ,2017 ,35 (5 ):148 -155 .
[本文引用: 1]
[4]
熊琦 人工智能生成内容的著作权认定
[J]. 知识产权 ,2017 (3 ):3 -8 .
[本文引用: 1]
[5]
乔丽春 “独立创作”作为“独创性”内涵的证伪
[J]. 知识产权 ,2011 (7 ):35 -38 .
[本文引用: 1]
[6]
姜颖 作品独创性判定标准的比较研究
[J]. 知识产权 ,2004 (3 ):8 -15 .
[本文引用: 1]
[7]
易继明 人工智能创作物是作品吗?
[J]. 法律科学(西北政法大学学报) ,2017 ,35 (5 ):137 -147 .
[本文引用: 1]
[8]
乔俊飞、韩红桂 RBF神经网络的结构动态优化设计
[J]. 自动化学报 ,2010 ,36 (6 ):865 -872 .
[本文引用: 1]
[9]
浅谈ChatGPT工作原理及机器学习和神经网络的训练
[EB/OL].(2023-03-14 )[2023-04-02 ]. .
URL
[本文引用: 1]
[10]
陶哲轩:ChatGPT已加入我的数学工作流
[EB/OL]. (2023-03-11 )[2023-04-02 ]. .
URL
[本文引用: 1]
[11]
黑格尔 美学(第一卷) [M]. 朱光潜 译 . 北京 :北京大学出版社 ,2017 .
[本文引用: 1]
[12]
叶朗 现代美学体系 [M]. 北京 :北京大学出版社 ,2004 .
[本文引用: 1]
[13]
陈虎 论人工智能生成内容的不可版权性:以表现形式为中心
[J/OL]. 重庆大学学报(社会科学版) :1 -13 [2023-06-14 ]. .
URL
[本文引用: 2]
[14]
金春阳 ,邢贺通 人工智能出版物版权归属及侵权归责原则研究
[J]. 出版发行研究 ,2021 (9 ):73 -81 .
[本文引用: 1]
[15]
曹源 人工智能创作物获得版权保护的合理性
[J]. 科技与法律 ,2016 (3 ):488 -508 .
[本文引用: 1]
[16]
MARK A L 杜颖 ,兰振国 财产权、知识产权和搭便车
[J]. 私法 ,2012 ,19 (1 ):123 -162 .
[本文引用: 3]
[17]
熊琦 著作权激励机制的法律构造 [M]. 北京 :中国人民大学出版社 ,2011 .
[本文引用: 2]
[19]
亚伦·普赞诺斯基 ,杰森·舒尔茨 所有权的终结:数字时代的财产保护 [M]. 赵精武 译 . 北京 :北京大学出版社 ,2022 .
[本文引用: 2]
[21]
肖海 ,张坤生 人工智能创作物视阈下版权法的反思与重构
[J]. 重庆理工大学学报(社会科学) ,2021 (9 ):156 -162 .
[本文引用: 1]
[22]
姚叶 多维度解读与选择:人工智能算法知识产权保护路径探析
[J]. 科技与法律(中英文) ,2022 ,7 (1 ):53 -61 .
[本文引用: 1]
[23]
彼得·德霍斯 知识财产法哲学 [M]. 周林 译 . 北京 :商务印书馆 ,2017 .
[本文引用: 1]
[24]
Copyright registration guidance: works containing material generated by artificial intelligence
(2023-03-16 )[2023-04-03 ]. .
URL
[本文引用: 2]
人工智能生成作品的著作权法之问
1
2020
... 随着人工智能生成内容技术(artificial intelligence generated content,以下简称AIGC)的迅速崛起,人类似乎正式开启了全面通往“数字时代”的新征程.AIGC是指利用人工智能技术进行文字、图像、视频、音频、游戏等内容的自动化输出;而ChatGPT就是一个基于GPT-3.5架构的大型语言模型,其技术路线是通过使用神经网络和自然语言处理技术,形成强大的语言理解和生成能力.ChatGPT的出现大幅度提升了AIGC技术的生成效率与输出语言内容的丰富度,并被广泛部署于对话交互、文本写作、文本翻译等应用场景;可以说,ChatGPT是实现AIGC技术突破的重要标志.既然以ChatGPT为代表的AIGC新技术已使人工智能实现了如此强大的智能水平和创作能力,那么人工智能生成内容是否能够受到版权意义上的保护?在以往研究中,已有不少关于人工智能生成内容可版权性问题的学术探讨,但这些学术成果多是对传统人工智能生成技术进行的回应.[1 ,2 ,3 ,4 ] 与传统技术相比,ChatGPT等大语言模型人工智能在文字理解力、文本处理量、文本输出速度等方面均取得了飞跃性进步,其强大的技术优势也催生了该行业新的运营模式和发展进路.因此,笔者将以ChatGPT生成内容为例,结合AIGC新技术的发展现状和行业特点,尝试对人工智能生成内容的可版权性问题进行回应. ...
人工智能智力成果在著作权法的正确定性:与王迁教授商榷
1
2018
... 随着人工智能生成内容技术(artificial intelligence generated content,以下简称AIGC)的迅速崛起,人类似乎正式开启了全面通往“数字时代”的新征程.AIGC是指利用人工智能技术进行文字、图像、视频、音频、游戏等内容的自动化输出;而ChatGPT就是一个基于GPT-3.5架构的大型语言模型,其技术路线是通过使用神经网络和自然语言处理技术,形成强大的语言理解和生成能力.ChatGPT的出现大幅度提升了AIGC技术的生成效率与输出语言内容的丰富度,并被广泛部署于对话交互、文本写作、文本翻译等应用场景;可以说,ChatGPT是实现AIGC技术突破的重要标志.既然以ChatGPT为代表的AIGC新技术已使人工智能实现了如此强大的智能水平和创作能力,那么人工智能生成内容是否能够受到版权意义上的保护?在以往研究中,已有不少关于人工智能生成内容可版权性问题的学术探讨,但这些学术成果多是对传统人工智能生成技术进行的回应.[1 ,2 ,3 ,4 ] 与传统技术相比,ChatGPT等大语言模型人工智能在文字理解力、文本处理量、文本输出速度等方面均取得了飞跃性进步,其强大的技术优势也催生了该行业新的运营模式和发展进路.因此,笔者将以ChatGPT生成内容为例,结合AIGC新技术的发展现状和行业特点,尝试对人工智能生成内容的可版权性问题进行回应. ...
论人工智能生成的内容在著作权法中的定性
1
2017
... 随着人工智能生成内容技术(artificial intelligence generated content,以下简称AIGC)的迅速崛起,人类似乎正式开启了全面通往“数字时代”的新征程.AIGC是指利用人工智能技术进行文字、图像、视频、音频、游戏等内容的自动化输出;而ChatGPT就是一个基于GPT-3.5架构的大型语言模型,其技术路线是通过使用神经网络和自然语言处理技术,形成强大的语言理解和生成能力.ChatGPT的出现大幅度提升了AIGC技术的生成效率与输出语言内容的丰富度,并被广泛部署于对话交互、文本写作、文本翻译等应用场景;可以说,ChatGPT是实现AIGC技术突破的重要标志.既然以ChatGPT为代表的AIGC新技术已使人工智能实现了如此强大的智能水平和创作能力,那么人工智能生成内容是否能够受到版权意义上的保护?在以往研究中,已有不少关于人工智能生成内容可版权性问题的学术探讨,但这些学术成果多是对传统人工智能生成技术进行的回应.[1 ,2 ,3 ,4 ] 与传统技术相比,ChatGPT等大语言模型人工智能在文字理解力、文本处理量、文本输出速度等方面均取得了飞跃性进步,其强大的技术优势也催生了该行业新的运营模式和发展进路.因此,笔者将以ChatGPT生成内容为例,结合AIGC新技术的发展现状和行业特点,尝试对人工智能生成内容的可版权性问题进行回应. ...
人工智能生成内容的著作权认定
1
2017
... 随着人工智能生成内容技术(artificial intelligence generated content,以下简称AIGC)的迅速崛起,人类似乎正式开启了全面通往“数字时代”的新征程.AIGC是指利用人工智能技术进行文字、图像、视频、音频、游戏等内容的自动化输出;而ChatGPT就是一个基于GPT-3.5架构的大型语言模型,其技术路线是通过使用神经网络和自然语言处理技术,形成强大的语言理解和生成能力.ChatGPT的出现大幅度提升了AIGC技术的生成效率与输出语言内容的丰富度,并被广泛部署于对话交互、文本写作、文本翻译等应用场景;可以说,ChatGPT是实现AIGC技术突破的重要标志.既然以ChatGPT为代表的AIGC新技术已使人工智能实现了如此强大的智能水平和创作能力,那么人工智能生成内容是否能够受到版权意义上的保护?在以往研究中,已有不少关于人工智能生成内容可版权性问题的学术探讨,但这些学术成果多是对传统人工智能生成技术进行的回应.[1 ,2 ,3 ,4 ] 与传统技术相比,ChatGPT等大语言模型人工智能在文字理解力、文本处理量、文本输出速度等方面均取得了飞跃性进步,其强大的技术优势也催生了该行业新的运营模式和发展进路.因此,笔者将以ChatGPT生成内容为例,结合AIGC新技术的发展现状和行业特点,尝试对人工智能生成内容的可版权性问题进行回应. ...
“独立创作”作为“独创性”内涵的证伪
1
2011
... 在著作权理论构建中,黑格尔的“人格价值论”有力证明了这一制度设计的正当性.作者权体系的立法传统认为,作品应当具备“独创性”,即应当反映作者的“个性”,或传递作者的“思想、情感等”[5 ] ;作品是“人类创造力”的集中体现.[6 ] 由于人工智能技术的快速迭代,有学者认为,人工智能的生成过程已不再是机械地“创作”,而是在没有预设算法或者规则的情况下,通过机器的主动学习来进行“创作”,著作权法的保护应延伸到人工智能的创造内容.[7 ] 然而,笔者认为,即便是ChatGPT这样先进的人工智能,其“创作过程”仍是以“算法”为本源、以“数字”为基础的,对表现作者“个性”力所不及. ...
作品独创性判定标准的比较研究
1
2004
... 在著作权理论构建中,黑格尔的“人格价值论”有力证明了这一制度设计的正当性.作者权体系的立法传统认为,作品应当具备“独创性”,即应当反映作者的“个性”,或传递作者的“思想、情感等”[5 ] ;作品是“人类创造力”的集中体现.[6 ] 由于人工智能技术的快速迭代,有学者认为,人工智能的生成过程已不再是机械地“创作”,而是在没有预设算法或者规则的情况下,通过机器的主动学习来进行“创作”,著作权法的保护应延伸到人工智能的创造内容.[7 ] 然而,笔者认为,即便是ChatGPT这样先进的人工智能,其“创作过程”仍是以“算法”为本源、以“数字”为基础的,对表现作者“个性”力所不及. ...
人工智能创作物是作品吗?
1
2017
... 在著作权理论构建中,黑格尔的“人格价值论”有力证明了这一制度设计的正当性.作者权体系的立法传统认为,作品应当具备“独创性”,即应当反映作者的“个性”,或传递作者的“思想、情感等”[5 ] ;作品是“人类创造力”的集中体现.[6 ] 由于人工智能技术的快速迭代,有学者认为,人工智能的生成过程已不再是机械地“创作”,而是在没有预设算法或者规则的情况下,通过机器的主动学习来进行“创作”,著作权法的保护应延伸到人工智能的创造内容.[7 ] 然而,笔者认为,即便是ChatGPT这样先进的人工智能,其“创作过程”仍是以“算法”为本源、以“数字”为基础的,对表现作者“个性”力所不及. ...
RBF神经网络的结构动态优化设计
1
2010
... 不可否认,如今的人工智能生成内容在表现形式上已与人类作品几无差别.与使用普通算法的传统软件不同,以ChatGPT为代表的生成式人工智能(generative artificial intelligence)往往需要训练并创建不同类型的神经网络算法.神经网络的基本原理是运用大量简单的组件搭建一个灵活的“计算结构”,并让这个“结构”能够被逐步修改,以便从经验数据中充分学习.神经网络的实际学习过程,简言之,是以确定权重(或概率)的方式较好地“捕捉”输入值(见图1 ).[8 ] 此外,从目前神经网络的设置来看,ChatGPT等生成式人工智能的底层逻辑都是建立于数字之上;因此,当我们运用ChatGPT等生成式人工智能来处理文字、图像等素材时,仍需要将素材内容分配或转化成数字.[9 ] ...
浅谈ChatGPT工作原理及机器学习和神经网络的训练
1
... 不可否认,如今的人工智能生成内容在表现形式上已与人类作品几无差别.与使用普通算法的传统软件不同,以ChatGPT为代表的生成式人工智能(generative artificial intelligence)往往需要训练并创建不同类型的神经网络算法.神经网络的基本原理是运用大量简单的组件搭建一个灵活的“计算结构”,并让这个“结构”能够被逐步修改,以便从经验数据中充分学习.神经网络的实际学习过程,简言之,是以确定权重(或概率)的方式较好地“捕捉”输入值(见图1 ).[8 ] 此外,从目前神经网络的设置来看,ChatGPT等生成式人工智能的底层逻辑都是建立于数字之上;因此,当我们运用ChatGPT等生成式人工智能来处理文字、图像等素材时,仍需要将素材内容分配或转化成数字.[9 ] ...
陶哲轩:ChatGPT已加入我的数学工作流
1
... 基于神经网络结构的搭建,以ChatGPT为代表的生成式人工智能不再像传统软件那样死板,“它运行的逻辑不是基于经典函数 f =X →Y ,而是类似于概率函数kernelμ:X →Pr( Y );即输入是从一个概率分布μx f(x) 附近”.[10 ] 一方面,ChatGPT更为灵活,更擅长处理一些嘈杂无序的输入值;另一方面,ChatGPT的“生成思维”也更为发散,其输出并非某一确定值,而是随机的,输出值落在完美结果的附近. ...
1
2017
... 另外,ChatGPT的创作过程同样缺乏意志要素,即创作的主动性——在作品当中主动融入自己的情致、性格、偏好等——其往往需要借助创作者的灵感与想象力.黑格尔在《美学》中指出:“‘情致’是艺术创作的真正中心和适当领域.对于作品和观众来说,情致的表现是效果的主要来源.”[11 ] 因此,创作一方面要反映客观对象的某些属性和特征,另一方面也要加入主体情感等个性色彩.[12 ] 以计算为本位的ChatGPT,既不具备表达个性的情致等条件,也缺乏在事物之间创造联系的无拘无束的想象力.可以说,ChatGPT的内容生成是建立在人类既有经验素材基础上的,其本身缺乏能力来拓展创作与想象的边界.从这一视角来看,ChatGPT生成内容具有不同程度的“同质性”,并非著作权所保护的目标对象.[13 ] ...
1
2004
... 另外,ChatGPT的创作过程同样缺乏意志要素,即创作的主动性——在作品当中主动融入自己的情致、性格、偏好等——其往往需要借助创作者的灵感与想象力.黑格尔在《美学》中指出:“‘情致’是艺术创作的真正中心和适当领域.对于作品和观众来说,情致的表现是效果的主要来源.”[11 ] 因此,创作一方面要反映客观对象的某些属性和特征,另一方面也要加入主体情感等个性色彩.[12 ] 以计算为本位的ChatGPT,既不具备表达个性的情致等条件,也缺乏在事物之间创造联系的无拘无束的想象力.可以说,ChatGPT的内容生成是建立在人类既有经验素材基础上的,其本身缺乏能力来拓展创作与想象的边界.从这一视角来看,ChatGPT生成内容具有不同程度的“同质性”,并非著作权所保护的目标对象.[13 ] ...
论人工智能生成内容的不可版权性:以表现形式为中心
2
... 另外,ChatGPT的创作过程同样缺乏意志要素,即创作的主动性——在作品当中主动融入自己的情致、性格、偏好等——其往往需要借助创作者的灵感与想象力.黑格尔在《美学》中指出:“‘情致’是艺术创作的真正中心和适当领域.对于作品和观众来说,情致的表现是效果的主要来源.”[11 ] 因此,创作一方面要反映客观对象的某些属性和特征,另一方面也要加入主体情感等个性色彩.[12 ] 以计算为本位的ChatGPT,既不具备表达个性的情致等条件,也缺乏在事物之间创造联系的无拘无束的想象力.可以说,ChatGPT的内容生成是建立在人类既有经验素材基础上的,其本身缺乏能力来拓展创作与想象的边界.从这一视角来看,ChatGPT生成内容具有不同程度的“同质性”,并非著作权所保护的目标对象.[13 ] ...
... 另外,诉讼带来的可观收益将诱发“权利寻租”的产生.“权利寻租”固然会使权利人获益,但该收益“并非是通过生产性活动使社会总体财富增加,而是通过公权力保护实现财富转移”.[13 ] 也就是说,由于人的自利性,对人工智能生成内容赋权很可能造成大量版权资源集中于少数人之手,而这种版权上的“圈地”行为将严重破坏原本平衡的利益生态.另外,“权利寻租”和权利滥用还会导致行政资源和司法资源的巨大浪费,使得知识产权的管理和执行成本不断攀升、司法救济渠道被不当挤占.[21 ] 值得注意的是,相较于人类的创作过程,以ChatGPT为代表的人工智能新技术在生成内容时的速度更快、效率更高且“不眠不休”,那么由此造成的版权“圈地”行为和资源浪费问题也就愈发严峻和棘手. ...
人工智能出版物版权归属及侵权归责原则研究
1
2021
... 部分学者认为,赋予创造者(或投资者)人工智能生成内容的版权,能够鼓励人工智能的技术创新和产业发展,因为此举可以使人工智能生成内容产生与人类作品同样的版权收益.[14 ,15 ] 持该观点的学者无疑是希望加强创造者(或投资者)对人工智能生成内容的控制力,将人工智能生成内容的社会收益完全内部化,以实现人工智能产业增长的激励效果. ...
人工智能创作物获得版权保护的合理性
1
2016
... 部分学者认为,赋予创造者(或投资者)人工智能生成内容的版权,能够鼓励人工智能的技术创新和产业发展,因为此举可以使人工智能生成内容产生与人类作品同样的版权收益.[14 ,15 ] 持该观点的学者无疑是希望加强创造者(或投资者)对人工智能生成内容的控制力,将人工智能生成内容的社会收益完全内部化,以实现人工智能产业增长的激励效果. ...
财产权、知识产权和搭便车
3
2012
... 然而在设计激励机制时,无论是财产权还是类财产权保护的知识产权,都并非追求对权利客体的“完全控制”.财产权概念作为“权利束或权利集群”意味着财产利益必然是可以分割的,而如何分割、如何基于需要对相关利益进行取舍,则应当依照具体情况予以定夺.[16 ] 著作权保护客体是十分特殊的信息,而信息的特点在于:一方面,信息的消费具有非竞争性,即一些人对该产品的消费并不减少其他人对该产品的消费,增加消费者的边际成本为零;另一方面,信息的占有具有非排他性,即信息无法在事实上排他占有,没有产权设定则无法在市场中获得该信息的收益.[17 ] 由此可知,信息既需要在流转中实现增值,又需要以产权加以保护;而在信息上设定权利必然会限制信息的再利用——当付费成为使用信息的前提,信息的传播就会受阻. ...
... OpenAI这一做法的确经过慎思:首先,通过转让生成内容的权益,让用户对该内容负责,能够在某种程度上规避生成内容可能包含的侵权风险;其次,由于各国法律对人工智能生成内容可版权与否的态度尚不明朗、有无生成内容的版权收益尚不明确,那么选择“订阅制”运营模式将有益于带来更为稳定的收入流.最重要的是,OpenAI绕过“版权”而取道“订阅制”,实际上是实现了部分外部收益的内部化,且随着用户量的不断攀升,可以合理期待相关收益能在未来弥补前期大量的投资成本.值得关注的是,由于此类信息订阅服务的固定成本相当高,而边际成本相对很低,那么其吸纳的用户越多,其平均总成本也就越低;因此,服务提供者完全可以通过扩大交易范围来有效降低平均总成本(见图2 ).[16 ] 倘若在生成内容上设定版权,则很可能导致用户进入门槛的提高与用户数或用户使用量的锐减,与原本期望的收益模式相违背. ...
... 鼓励创作与信息传播之间的固有矛盾决定了对信息产品的赋权必须谨慎,因为在信息上设定排他性权利往往会与公众对已知信息的正常使用发生冲突;立法者只有对各方利益进行充分权衡,才能为新兴技术与公众生活的良性互动提供稳定预期.对于版权理论中对信息“独占”的强调,学者彼得·德霍斯(Peter Drahos)曾旗帜鲜明地指出,这种“独占”将会严重限制甚至威胁到公众的消极自由.[23 ] 相较于实物性财产,信息具有“公共产品”的特殊属性,可以被不同使用者同时获取,因而在信息上设定权利对公众生活的影响更大;此外,信息的传播与利用涉及诸多基本权利的实现,信息成了人们无法回避的“公共资源”.事实上,法律并不禁止作品之间的模仿,因为任何形式的创作都不可避免会涉及对已知信息的利用;对思想与表达进行“强制”区分的用意更多是据此来设定专有权利的保护范围,人为地制造出受保护客体的“稀缺性”.由于赋权会在保障私人收益的同时增加社会成本,有学者据此认为:“只有在能够使创造者收回平均固定成本的限度内才能给予知识产权,超出这一限度是有害无利的.”[16 ] ...
2
2011
... 然而在设计激励机制时,无论是财产权还是类财产权保护的知识产权,都并非追求对权利客体的“完全控制”.财产权概念作为“权利束或权利集群”意味着财产利益必然是可以分割的,而如何分割、如何基于需要对相关利益进行取舍,则应当依照具体情况予以定夺.[16 ] 著作权保护客体是十分特殊的信息,而信息的特点在于:一方面,信息的消费具有非竞争性,即一些人对该产品的消费并不减少其他人对该产品的消费,增加消费者的边际成本为零;另一方面,信息的占有具有非排他性,即信息无法在事实上排他占有,没有产权设定则无法在市场中获得该信息的收益.[17 ] 由此可知,信息既需要在流转中实现增值,又需要以产权加以保护;而在信息上设定权利必然会限制信息的再利用——当付费成为使用信息的前提,信息的传播就会受阻. ...
... 知识产权法用以维系权利排他性的方法之一是抡起侵权责任的“大棒”.然而在数字信息时代,权利人尽最大努力也很难起诉到每一个下载、复制或传播盗版内容的人;即使能够起诉,其举证难度也颇大,起诉成功的概率很低,权利得到救济的可能性十分有限.[19 ] 同理,倘若给予创造者(或投资者)以人工智能生成内容版权,那么由于服务平台的用户数和用户使用量巨大,将存在数量惊人且分布在世界各地的潜在侵权人;而一些相关网络社群的出现,则很可能使侵权发生得更加容易.由此可见,赋权将会导致维权成本居高不下,权利救济十分困难,甚至权利运行本身难以为继.[17 ] ...
Pricing
1
... 因此,在人工智能生成内容之上设定权利并非越多越好,我们必须慎思信息类产品外部收益的内部化程度,即收益的内部化应足以补偿相应投资并获取合理利润,但不能过度.以当前ChatGPT的收益模式为例,ChatGPT的运营采用“订阅制”模式:ChatGPT-3.5网页端提供免费服务,GPT-4(ChatGPT Plus)网页端提供20美元/月的收费服务;两版ChatGPT接入应用程序编程接口(application programming interface,以下简称API)的服务均按照客户端向服务端请求数据量(tokens)进行收费(GPT-4此类服务收费更高).[18 ] “订阅制”服务在价格、选择和灵活性方面都颇具吸引力,大众消费者很容易被征服;如网飞、Hulu等视频网站,Playstation Now、EA Access等在线视频游戏库,以及Photoshop等应用程序软件均通过“订阅制”向客户提供服务,这为公司带来了相对可预测的收入流.[19 ] 可以说,后数字时代的信息传递与保护已呈现出从“产权设定”到“订阅服务”的转型;ChatGPT的运营者OpenAI在商业发展规划上,也战略性地舍弃了将其生成内容版权化的产权收益模式.ChatGPT“用户使用条款”明确写道:“用户可以向服务提供输入(‘输入’),并接收服务根据输入产生和返回的输出(‘输出’),输入和输出统称为‘内容’.在两者之间以及在适用法律允许的范围内,用户拥有所有输入内容;用户如遵守这些使用条款,OpenAI将特此向用户转让其对输出的所有权利、所有权和利益.OpenAI可在必要时使用内容以提供和维护服务、遵守适用的法律和执行我们的政策.用户须对内容负责,包括确保其不违反任何适用法律或这些使用条款.”[20 ] ①
2
2022
... 因此,在人工智能生成内容之上设定权利并非越多越好,我们必须慎思信息类产品外部收益的内部化程度,即收益的内部化应足以补偿相应投资并获取合理利润,但不能过度.以当前ChatGPT的收益模式为例,ChatGPT的运营采用“订阅制”模式:ChatGPT-3.5网页端提供免费服务,GPT-4(ChatGPT Plus)网页端提供20美元/月的收费服务;两版ChatGPT接入应用程序编程接口(application programming interface,以下简称API)的服务均按照客户端向服务端请求数据量(tokens)进行收费(GPT-4此类服务收费更高).[18 ] “订阅制”服务在价格、选择和灵活性方面都颇具吸引力,大众消费者很容易被征服;如网飞、Hulu等视频网站,Playstation Now、EA Access等在线视频游戏库,以及Photoshop等应用程序软件均通过“订阅制”向客户提供服务,这为公司带来了相对可预测的收入流.[19 ] 可以说,后数字时代的信息传递与保护已呈现出从“产权设定”到“订阅服务”的转型;ChatGPT的运营者OpenAI在商业发展规划上,也战略性地舍弃了将其生成内容版权化的产权收益模式.ChatGPT“用户使用条款”明确写道:“用户可以向服务提供输入(‘输入’),并接收服务根据输入产生和返回的输出(‘输出’),输入和输出统称为‘内容’.在两者之间以及在适用法律允许的范围内,用户拥有所有输入内容;用户如遵守这些使用条款,OpenAI将特此向用户转让其对输出的所有权利、所有权和利益.OpenAI可在必要时使用内容以提供和维护服务、遵守适用的法律和执行我们的政策.用户须对内容负责,包括确保其不违反任何适用法律或这些使用条款.”[20 ] ①
... 知识产权法用以维系权利排他性的方法之一是抡起侵权责任的“大棒”.然而在数字信息时代,权利人尽最大努力也很难起诉到每一个下载、复制或传播盗版内容的人;即使能够起诉,其举证难度也颇大,起诉成功的概率很低,权利得到救济的可能性十分有限.[19 ] 同理,倘若给予创造者(或投资者)以人工智能生成内容版权,那么由于服务平台的用户数和用户使用量巨大,将存在数量惊人且分布在世界各地的潜在侵权人;而一些相关网络社群的出现,则很可能使侵权发生得更加容易.由此可见,赋权将会导致维权成本居高不下,权利救济十分困难,甚至权利运行本身难以为继.[17 ] ...
Terms of use
1
... 因此,在人工智能生成内容之上设定权利并非越多越好,我们必须慎思信息类产品外部收益的内部化程度,即收益的内部化应足以补偿相应投资并获取合理利润,但不能过度.以当前ChatGPT的收益模式为例,ChatGPT的运营采用“订阅制”模式:ChatGPT-3.5网页端提供免费服务,GPT-4(ChatGPT Plus)网页端提供20美元/月的收费服务;两版ChatGPT接入应用程序编程接口(application programming interface,以下简称API)的服务均按照客户端向服务端请求数据量(tokens)进行收费(GPT-4此类服务收费更高).[18 ] “订阅制”服务在价格、选择和灵活性方面都颇具吸引力,大众消费者很容易被征服;如网飞、Hulu等视频网站,Playstation Now、EA Access等在线视频游戏库,以及Photoshop等应用程序软件均通过“订阅制”向客户提供服务,这为公司带来了相对可预测的收入流.[19 ] 可以说,后数字时代的信息传递与保护已呈现出从“产权设定”到“订阅服务”的转型;ChatGPT的运营者OpenAI在商业发展规划上,也战略性地舍弃了将其生成内容版权化的产权收益模式.ChatGPT“用户使用条款”明确写道:“用户可以向服务提供输入(‘输入’),并接收服务根据输入产生和返回的输出(‘输出’),输入和输出统称为‘内容’.在两者之间以及在适用法律允许的范围内,用户拥有所有输入内容;用户如遵守这些使用条款,OpenAI将特此向用户转让其对输出的所有权利、所有权和利益.OpenAI可在必要时使用内容以提供和维护服务、遵守适用的法律和执行我们的政策.用户须对内容负责,包括确保其不违反任何适用法律或这些使用条款.”[20 ] ①
人工智能创作物视阈下版权法的反思与重构
1
2021
... 另外,诉讼带来的可观收益将诱发“权利寻租”的产生.“权利寻租”固然会使权利人获益,但该收益“并非是通过生产性活动使社会总体财富增加,而是通过公权力保护实现财富转移”.[13 ] 也就是说,由于人的自利性,对人工智能生成内容赋权很可能造成大量版权资源集中于少数人之手,而这种版权上的“圈地”行为将严重破坏原本平衡的利益生态.另外,“权利寻租”和权利滥用还会导致行政资源和司法资源的巨大浪费,使得知识产权的管理和执行成本不断攀升、司法救济渠道被不当挤占.[21 ] 值得注意的是,相较于人类的创作过程,以ChatGPT为代表的人工智能新技术在生成内容时的速度更快、效率更高且“不眠不休”,那么由此造成的版权“圈地”行为和资源浪费问题也就愈发严峻和棘手. ...
多维度解读与选择:人工智能算法知识产权保护路径探析
1
2022
... 生成式人工智能对创作方式和创作生态的改造将带来以下后果:一方面,随着该技术的成熟与普及,会有海量满足“最低限度的创造性”的作品被源源不断地生产出来,而由于数量之巨大,这些作品的价值会被迅速“摊薄”成为“非稀缺”物品;由于对“非稀缺”物品设定产权是冗余的,那么对生成内容赋权的必要性就随之丧失.[22 ] 另一方面,在资源有限的情况下,激励机制往往倾向于把权利分配给“最有效率”的资源使用者;著作权法的立法动机固然是要保护所有进行独创性表达的作者,但也“青睐”于激励作者中更具创造力和想象力的人——换言之,在创作领域“最有效率”的赋权对象通常是科技文化从业者或相关专业人士,因为他们更有可能基于激励持续创作出高质量的作品.然而,在生成式人工智能的加持下,人工智能使用者们已皆为“作家”或“画家”,市场无法将专业的创作人士区分出来;因此,向人工智能使用者赋权很有可能导致版权的实际赋予者和目标赋予者错位,出现激励偏差.除此之外,将版权赋予使用者,很可能会导致使用者的“创作惰性”,因为既然可以直接依托人工智能生成有版权的作品,那何必自己进行创新?ChatGPT等生成式人工智能最终反而成了“代替”人类进行创新和思考的巨大威胁. ...
1
2017
... 鼓励创作与信息传播之间的固有矛盾决定了对信息产品的赋权必须谨慎,因为在信息上设定排他性权利往往会与公众对已知信息的正常使用发生冲突;立法者只有对各方利益进行充分权衡,才能为新兴技术与公众生活的良性互动提供稳定预期.对于版权理论中对信息“独占”的强调,学者彼得·德霍斯(Peter Drahos)曾旗帜鲜明地指出,这种“独占”将会严重限制甚至威胁到公众的消极自由.[23 ] 相较于实物性财产,信息具有“公共产品”的特殊属性,可以被不同使用者同时获取,因而在信息上设定权利对公众生活的影响更大;此外,信息的传播与利用涉及诸多基本权利的实现,信息成了人们无法回避的“公共资源”.事实上,法律并不禁止作品之间的模仿,因为任何形式的创作都不可避免会涉及对已知信息的利用;对思想与表达进行“强制”区分的用意更多是据此来设定专有权利的保护范围,人为地制造出受保护客体的“稀缺性”.由于赋权会在保障私人收益的同时增加社会成本,有学者据此认为:“只有在能够使创造者收回平均固定成本的限度内才能给予知识产权,超出这一限度是有害无利的.”[16 ] ...
Copyright registration guidance: works containing material generated by artificial intelligence
2
... 美国版权局于2023年3月发表了一份政策声明,作为生成式人工智能迅速崛起之下其生成内容可版权性问题的首批回应.目前,美国版权局已收到一批包含有人工智能生成内容的作品注册申请,例如,由人类创作者所编写文本和人工智能所生成图像组成的图像小说.美国版权局认为,人类创作者可拥有作品中的文本以及图文编排部分的版权,但作品中由人工智能所生成的图像需要被排除在外;其原因在于“要成为‘作者’的作品,必须由人创造,而该局不会注册由机器或仅仅是随机或自动运行的机械过程所产生的作品,而没有人类作者的任何创造性投入或干预……版权局首先会询问这一作品是否基本上是人类的作品,而计算机(或其他设备)只是一种辅助工具,或者作品中的传统作者要素(文学、艺术、音乐表达或选择、安排等要素)实际上不是由人而是由机器构思和执行的”.[24 ] ① [24 ] ②
... [24 ]②



{kind=link}
{kind=link}
{kind=link}
{kind=link}