

1 前言
其中关于AIGC技术对于出版的破坏力是科研领域的重要议题之一[4,5],来自Gao的研究已经明确地向我们展示了利用ChatGPT生成的英文学术摘要足以骗过期刊审稿人。[6]这些借助ChatGPT在内的AIGC技术生成的单词、短语和句子的新组合,往往难辨真伪。因此,有些人和公司开始利用这些技术制造一些虚假学术论文和研究报告,以欺骗学术出版机构、学界同人,乃至公众。《科学》(Science)杂志已经明确提出不得将ChatGPT等AI工具作为文章的贡献者,并且将类似的行为定义为学术不端。[7,8]笔者已经在编辑学的期刊中收到过类似“综述”类文献的审稿邀请,目测AI代写的比例相当高。所以“反AI”的工作已经成为国内外学术期刊同人必须面对的现实问题,我们需要呼吁对于类ChatGPT工具生产的文本开展检测工作,以协助编辑在评审过程中发现类似的学术不端行为。目前国内有过基于ChatGPT技术特征的分析,但真正开展AI检测的工作尚未实践应用起来。[9]
为了验证AIGC技术对学术期刊出版的挑战以及AI检测工具的价值,我们设计了本试验,本试验生成了人类和人工智能写作的各50篇文章,分别交由专业编辑进行测试,将两组的结果进行分析比较,以期实现两项目标:一是验证AIGC生成内容对于国内学术期刊文字相似性检测系统的逃脱能力,二是验证国内某AI检测工具的判别能力。
2 方法
2.1 待检测文本的准备
研究组利用“中华医学期刊全文数据库”随机选取2022年发表在中华医学会系列期刊中带有中文摘要的100篇综述类文献,从中截取中文摘要以及关键词。入选的100段文字在不改变主体内容的前提下,做了部分的数据处理,包括去除HTML标记、样式代码并合并段落。
利用随机数法将100篇文献随机分为两组:原文对照组(50篇)和AI生成组(50篇)。其中对照组不做任何处理,AI生成组通过ChatGPT4.0利用其中文文题和中文关键词信息生成摘要文本。使用提示语(prompt)如下:假设你是医学领域的作者,按照以下样例写一段标题为“[title]”的综述性文章的摘要。文字不超过500个汉字。建议文字尽可能含有以下关键词:“[keywords]”。摘要内容不可以分段。不能用首先、其次、最后、综上所述等文字。参考的样例如下:糖尿病并发症是导致糖尿病患者致残甚至致命的主要原因,而作为细胞能量代谢的中心,线粒体功能障碍与多种并发症的发生和发展密切相关。本文综述了糖尿病常见的微血管并发症,包括糖尿病溃疡、糖尿病肾病和糖尿病视网膜病变等,并阐述了其病理机制涉及线粒体功能和氧化应激的研究进展。通过对线粒体氧化应激的理解,我们为针对这些疾病进行靶向线粒体氧化应激治疗提供了更多的理论基础。其中[title]为原文献标题,[keywords]为原文献的关键词。以上提示语及生成的文本见SciDB数据库(DOI:10.57760/sciencedb.09563)。
为避免AI生成的内容出现过多特征性的文本,课题组要求文本不得出现明显的分段性内容和层次化的词汇,一旦ChatGPT生成有类似内容时,研究组给予新的提示词将生成的文字按照样例重新编写,直至不再出现类似词汇。新的提示如下:“请将文本A的内容按照文本B的内容重新写,文本A: [text A]。文本B: [text B]。”其中text A为之前AI生成的文字,text B为第一问的示例。
最后,研究组对于以上生成文本做一遍通读工作,进一步优化去除可能会引起测试对象警觉的特征性文字。将以上100篇文献随机编号后,打乱次序生成问卷表待用(问卷表原件参见SciDB数据库,DOI:10.57760/sciencedb.09563)。
2.2 文献相似性检测
将上述两组文本分别合成为两个独立文档,利用“万方数据文献相似性检测系统”分别对其进行检测。
将上述2组文本分别合成为2个独立文档,利用“万方数据文献相似性检测系统”对其进行检测,检测时间为2023年7月12日。检测相似文献数据库包括中国学术期刊数据库、优先出版论文数据库、国内外重要学术会议论文数据库、中国博士学位论文全文数据库、中国优秀硕士学位论文全文数据库、中国优秀报纸全文数据库、互联网学术资源数据库、学术网络文献数据库、中国专利文献全文数据库、特色英文文摘数据库和中国标准全文数据库,获得参考文献相似比、辅助排除参考文献相似比、可能自引相似比和辅助排除可能自引相似比等检测结果。
2.3 入选评审者以及AI检测器
(1)将上述问卷表发至人选评审者,要求评审者评判100段文本是由人类或者AI写作。为保证入选者对于学术期刊的编辑有丰富的经验,课题组要求所有入选者必须同时具备以下资质:①中级及以上编辑职称;②编龄超过5年;③目前从事编辑工作;④具备医学领域的学历背景。
(2)要求所有评审者在不借助任何工具的情况下对100篇文本进行判别(不借助任何工具包括不通过数据库检索、不通过工具书审查相关知识、不通过任何AI检测工具进行检测等),完全凭借个人认知对文本内容开展独立判别工作。
(3)专家组发放时间为2023年7月10日,回收时间为7月10—14日,共发放17份,回收17份,回收率100%,剔除2份不合格问卷(一份为评审者不再从事编辑工作,一份编辑职称不达标),得到有效问卷15份。
(4)在发放给评审者进行评判的同时将上述文本通过国内的一款AI检测器(商品名:鉴字源,软件开发公司:南京智齿数汇科技有限公司,版本号:1.7.0)进行判别,以AI写作比例超过0.7作为高风险论文,0.6~0.7为中风险,以上两者认定该文献为AI写作;0.5~0.6为低风险,0.5以下归为无风险,以上两者认定该文献归为人类写作。AI检测器检测时间为2023年7月17日22:00—23:00。取所有文本检测的AI写作的总体概率值以及判定结果纳入本研究(图1)。
图1
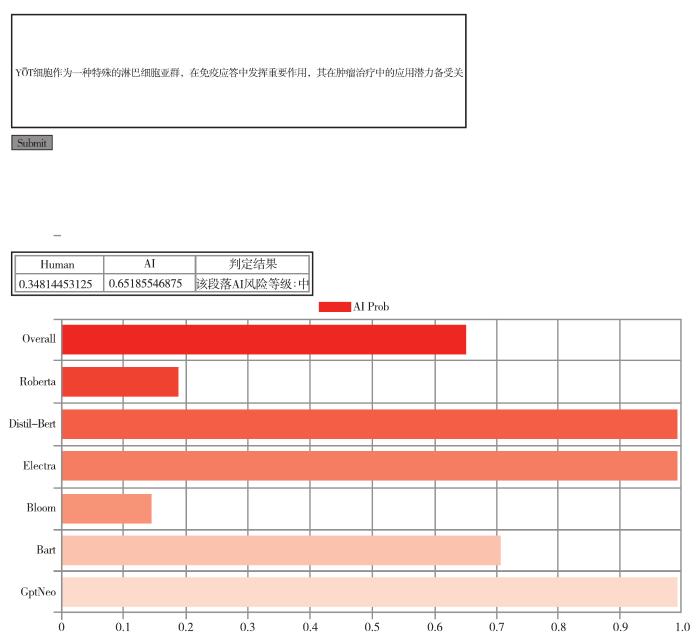
(5)此外,课题组进一步基于ChatGPT4.0开展AI写作的判别工作,但多次检测发现,ChatGPT的回复结论存在漂移,同一文本判别的结果不尽相同,课题组判断ChatGPT缺乏评价的功能,故其数据不再作为后续比较的结果。
2.4 统计学方法
本研究将AI判别调查表的结果收集汇总后,应用Excel软件进行统一数据录入工作,通过SPSS 24.0软件开展统计学分析,并采用两个独立样本卡方检验检验组间率的比较。统计分析使用双侧检验,检验水平α取0.05,P<0.05表示差异有统计学意义。
3 结果
3.1 文献相似性检测结果
课题组对两组文本均进行了基于文字的相似性检测,结果见表1。结果显示由ChatGPT生成的文本在相似性比例仅有6.19%,而原文对照组的文献相似比高达55.91%。原文对照组高相似比的原因是这些文字发表于2022年,大部分内容已被该学术不端检测系统所收录,检测时易发现存在的类似文本。课题组对AI写作组的报告进行细节评判,发现其文字相似点的分布非常零碎,几乎不存在大段文本,甚至整句的重复,只有个别字词的重复,严格来说可以不纳入相似内容(以上检测报告见SciDB数据库,DOI:10.57760/sciencedb.09563)。结果说明,AI写作的文本通过文献相似性检测的概率远远高于人类写作的文本(P<0.01),也提示传统的基于文字的相似性学术不端检测系统对于AIGC的文本无能为力。
表1 文献相似性检测平台对两组文本的检测结果
| 组别 | 检测字符数 | 参考文献相似比/% | 辅助排除参考文献相似比/% | 可能自引相似比/% | 辅助排除可能自引相似比/% | P值 |
| 原文对照组 | 10 607 | 0.00 | 55.91 | 0.00 | 55.91 | <0.001 |
| AI写作组 | 15 525 | 0.00 | 6.19 | 0.00 | 6.19 |
* P值为两组间辅助排除可能自引相似比的比较。
3.2 AI检测器的检测结果
表2 使用AI检测工具对两组文本的AI写作检测结果
| 组别 | 样本量 | 认定非AI写作比例(篇/%) | 认定AI写作比例(篇/%) | |||||
| 无AI风险 | 低AI风险 | 合计 | 中AI风险 | 高AI风险 | 合计 | P值* | ||
| 原文对照组 | 50 | 46/92.0 | 2/4.0 | 48/96.0 | 2/4.0 | 0 | 2/4.0 | <0.01 |
| AI写作组 | 50 | 11/22.0 | 6/12.0 | 17/34.0 | 8/16.0 | 25/50.0 | 33/66.0 | |
* P值为两组间认定AI写作准确性的比较。
3.3 评审者人工评判结果
本研究入选有效问卷15份,15位评审者的基本信息汇总见表3。从入选者的情况来观察,平均编龄15年,高级职称占53.4%,硕士研究生及以上学历占86.6%,所有评审者都具备医学领域的学习背景,并处于在职工作中,说明本次评审组具备基本良好的编辑素质和医学专业素养。
表3 入选有效评审者基本情况
| 项目 | 数值 |
| 总数(人) | 15 |
| 编龄[年,M(范围)] | 15(6~23) |
| 职称(人/占比) | |
| 正高 | 1/6.7% |
| 副高 | 7/46.7% |
| 中级 | 7/46.7% |
| 最高学位(人/占比) | |
| 博士 | 2/13.3 |
| 硕士 | 11/73.3 |
| 学士 | 2/13.3% |
| 具备医学背景(人) | 15 |
| 接触AIGC(人/占比) | |
| 是 | 2/13.3% |
| 否 | 13/86.7% |
| 接触AIGC频率(人/占比) | |
| 从未 | 13/86.7% |
| 偶然(一月几次) | 1/6.7% |
| 一般(一周1~5次) | 1/6.7% |
| 频繁(一周5次以上) | 0 |
15位评审者对上述100篇文本的AI写作判别结果见表4。对于原文对照组,认定准确的概率为85.3%;对于AI写作组,认定准确的概率为70.4%,整体的平均准确度为77.9%。评审者在判断两组文本存在一定的假阳性率(14.7%)和假阴性率(29.6%),但对于原文的判别准确性稍高于AI写作的文本(85.3%比70.4%,P<0.01)。
表4 评审者对两组文本的AI写作判别结果(n=15)
| 组别 | 样本量 | 认定AI写作比例/% | 认定非AI写作比例/% | P值* |
| 原文对照组 | 50 | 14.7 | 85.3 | <0.01 |
| AI写作组 | 50 | 70.4 | 29.6 |
* P值为两组间认定AI写作准确性的比较,认定AI写作比例与认定非AI写作比例取15位评审者的算术平均数。
3.4 评审者人工评判与AI检测工具之间的比较结果
表5 评审者与AI检测工具判别结果比较
| 组别 | 整体准确性/% | P值 | 假阳性率/% | P值 | 假阴性率/% | P值 |
| 评审者 | 77.9 | 0.463 | 14.7 | <0.01 | 29.6 | 0.352 |
| AI检测工具 | 81.0 | 4.0 | 34.0 |
4 讨论
4.1 AIGC技术的发展对现有学术不端检测系统带来了极大的挑战
国外已经有学者的研究表明AI生成的摘要是完全可以通过文字相似性检测的,我们的研究进一步验证了这个结果,由ChatGPT4.0生成的摘要整体的相似度仅有6.19%,暴露了现有检测系统的无力。在AIGC时代我们的挑战更多,涌现的各种工具生成内容新颖,逻辑清晰,甚至超过了大部分人类的水平,所以其剽窃行为更为隐蔽,使得依赖文字相似性分析或复杂机器学习的检测系统无法有效应对。这是对我们的警告,学术期刊必须升级现有系统以应对AIGC技术带来的问题。
4.2 面对AIGC滥用所致的学术诚信问题制定事前预警机制迫在眉睫
本次试验的结果说明,AI检测工具已经基本达到高级编辑的判别水平,可以帮助编辑初步分辨人类写作的内容,这对于学术期刊的编辑可以起到非常重要的作用,但从另一指标我们也发现,对于人工智能写作的文本,其判别准确度尚不能优于高级编辑,说明防范AI滥用的道路还是任重道远。
笔者在与评审者探讨过程中了解到,评审者可以从AIGC的文本中发现更多的AI写作可能缘于相较于对照组,AI组存在一些语言看似拗口的文本,致使评审者可以更多地发现哪些文本存在“伪造”情形,而对照组的文本均是已经发表的文献的摘要,经过编辑和作者的多轮修改和校对,各方面都处于完美的状态。但如果把真实场景考虑进去,稿件投递完成后编辑是需要在初审环节来判断稿件是否存在AI撰写的片段,此时的原稿尚未经过一系列的评审和编校,不可避免存在语病、语法不通,乃至知识错误,在此情形下,之前的那些差异点可能会被抹去,从而增加编辑判别的难度。所以在采编系统中引入必要的AI检测工具,可能会成为学术期刊采编系统的必备功能之一。
4.3 坚持人工验证,让人类成为作品的第一责任人
《自然》(Nature)杂志在“ChatGPT应用于科学研究的5个重点问题”[10]中提出要坚持人工验证,“对话式的人工智能回答专业问题,可能带来不准确、抄袭等问题……对于研究中使用到ChatGPT,人工核验步骤必不可少,甚至必要时可能需要禁用相关程序。因为,人类需要对科学实践负责”。笔者深以为然,本次研究证实AI的检测软件有效果,但不管成果如何,学术期刊的编辑以及评审团队永远都需要站在AI的反面去审查这些稿件。幸运的是,本次研究结果显示,专业编辑具备了基本的编辑素养,对于AIGC的内容是有鉴别能力的。
检测工具固然重要,但更重要的是建立科研诚信的问责制度,让作者成为论文的第一责任人,编辑及编委会团队成为科研诚信的监督员,对滥用AIGC的行为进行明确的规范和限制,采取更积极的手段,开发事前预警机制,在问题发生之前就进行预防和应对,而不仅仅是在问题发生后再进行反应。
4.4 AIGC的滥用与防范会是一场无休止的“猫鼠游戏”
作为一种先进的技术,AIGC能有效协助我们制作各类内容,大幅缩减人力资源投入,节省时间,提高工作效率。然而,像所有工具一样,AIGC会被滥用,有些人会利用它来抄袭、制造虚假数据或者从事其他不诚实的行为。为了遏制这种滥用现象,我们开始借助基于AI的检测工具,通过对文本结构、风格和模式的分析,来判断内容是否由AI生成。我们不断地借助这些工具来防止AIGC技术对科研诚信的破坏力,然而,挑战和对策始终是相对的,“道高一尺,魔高一丈”,AIGC能够通过精心设计的提示来消除某些规律性特征,例如,本研究中我们避免使用“首先”“其次”“综上所述”等用语并要求ChatGPT不进行自然分段,此外也可以改变单句的长度以逃避AI检测工具的监测。于是AI技术团队又需要进一步升级AI检测工具,以便更全面地捕捉AI生成内容的其他“蛛丝马迹”,然而AIGC的滥用者又不会甘拜下风,会借助新的技术来不断逃逸检测,因此,这场“猫鼠游戏”将永无休止。
5 结语
面对AIGC技术的汹涌而至,支持者弹冠相庆,反对者失声呐喊,对此应以平和客观的眼光看待。技术进步是不可阻挡的,我们无法避免新技术的出现,但也必须认识到,每一项新技术都有其潜在的风险和缺陷。
2023年7月10日,国家互联网信息办公室等七部委联合发布了《生成式人工智能服务管理暂行办法》。该办法自8月15日开始生效并明确指出,无论是提供还是使用生成式人工智能服务的一方,都应当遵守相关的法律法规,尊重社会公德,并恪守伦理道德。这是我国AIGC管理领域的里程碑,“道阻且长,行则将至;行而不辍,未来可期。”在推出类似的法规之后,还有更多的工作需要学术出版人去探索和执行。学术期刊人既要有“AI意识”,迎接和拥抱AI时代的到来,又要有“AI防范意识”,防范AI工具的不良作用。也就是说,一方面要充分利用AIGC的红利,服务于我们的作者、专家、编辑和用户;另一方面,我们还需对AIGC技术进行严格的监管和管理,确保其生成的内容能够符合期刊的质量标准,遵循期刊的学术规范。最后,我们也需要加强对AIGC技术的了解和研究,对AIGC应用进行更深远、更广泛的探讨,寻找更好的方法来利用这项技术,以推动学术期刊的繁荣于发展。
参考文献
Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers
[J].

{kind=link}
{kind=link}