

建构于人工神经网络、机器学习算法与大数据技术基础上的生成式人工智能,已能够自主生成具有强逻辑性、高复杂性与自然语言符合性的内容,从而部分或全部替代人类劳动,并在不断迭代升级。[1]目前,生成式人工智能已经深入影响经济社会各领域全流程[2],学术出版领域亦不例外。2023年《物理学手稿》学术期刊出版的论文,被图卢兹大学科学家卡巴拉卡发现是使用生成式人工智能所生成,因其中使用了生成式人工智能特有的“重新生成回答”术语,后该文因学术不端被撤稿。[3]无独有偶,同年我国科研人员在《资源政策》学术期刊上出版的论文,被发现使用了生成式人工智能专属“作为一个人工智能语言模型”术语,后被出版商爱思唯尔实施学术不端调查。[4]当前,此类使用生成式人工智能形成的学术成果进行出版,而被认定为违背学术出版伦理的案例不绝于耳,严重动摇了学术诚信底座。为维护学术出版秩序,捍卫科研透明与学术诚信,有必要对使用生成式人工智能产生的学术出版伦理冲击进行深入研究,从而提出相应的法律治理举措以规范科研人员使用生成式人工智能的行为,促进科学进步与出版产业健康发展。
1 使用生成式人工智能对学术出版伦理的挑战
生成式人工智能的出现,使得人们在知识储备、逻辑分析等方面的差异缩小。机械简单的提示词输入,便能够生成合乎逻辑和适合发表的学术内容。此种削减科研人员体力与脑力劳动投入的学术科研“革命”,对趋利性的科研人员具有巨大的诱惑力,使其具备更强的动因越过学术伦理“雷池”,以摘取学术不端的“禁果”。纵观生成式人工智能有关的社会实践,可能对学术出版伦理形成如下挑战。
其一,使用生成式人工智能冲击信息真实准确的学术出版伦理。生成式人工智能生成学术内容的方法本质是概率论的应用。既然是概率,那么便不具有必然性,因此存在输出内容无法反映外部世界真实的可能性,即输出内容的信息失真。此种生成式人工智能生成的失真信息与真实信息相悖,客观上可能构成学术不端行为的伪造。此时,使用生成式人工智能生成的失真信息,将会对要求信息真实准确的学术出版伦理形成挑战。
其二,使用生成式人工智能冲击信息可靠透明的学术出版伦理。生成式人工智能输出内容是以既有信息为基础的,其中包括他人研究成果。生成式人工智能输出的内容,既可能是生成式人工智能形成的原创性内容,也可能是他人论点、论据等成果。如果未经他人同意,擅自将生成式人工智能输出的他人成果,以自己名义发表,可能构成学术不端行为的剽窃;但如果经过他人同意,将生成式人工智能输出的他人成果,以自己的名义发表,则可能构成学术不端行为的代写。因此,科研人员使用生成式人工智能输出的内容作为自己的研究成果进行发表,将会对要求信息可靠透明、尊重他人知识产权的学术出版伦理形成挑战。
其三,使用生成式人工智能署名冲击文责自负的学术出版伦理。学术出版伦理要求出版内容应由署名者负担信息真实准确、可靠透明的伦理责任与法律责任,并在出版内容违反出版伦理时,接受相应的道德谴责与法律追责。学术出版伦理建立在“人类中心主义”哲学认识论基础上,只有人方为学术出版活动的参与主体。[5]生成式人工智能不是具有“羞耻心”与“荣誉感”的道德主体与责任能力的法律主体,无法承担学术责任。将其列为出版内容的署名者,可能构成学术不端行为的不当署名,将会对文责自负的学术出版伦理形成挑战。
2 使用生成式人工智能的学术出版伦理困境分析
2.1 使用生成式人工智能构成剽窃
剽窃是指利用不正当手段窃取论点、论据与成果,以自己名义使用发表的行为。此处“剽窃”,包含两个维度:剽窃生成式人工智能生成的学术内容和剽窃他人的学术成果。
2.1.1 是否构成剽窃生成式人工智能生成的学术内容
我国教育部颁布的《办法》与国家新闻出版署发布的《学术出版规范——期刊学术不端行为界定(CY/T174—2019)》(下文简称学术出版规范)规定的“剽窃”均是剽窃其他自然人的观点、数据、成果等,尚未明确剽窃人工智能生成内容是否构成剽窃。教育部颁布的《高等学校预防与处理学术不端行为办法》(下文简称《行为办法》)与《学位论文作假行为处理办法》(下文简称处理办法)也规定剽窃行为的对象应为“他人”成果。因此,使用生成式人工智能生成内容是否构成剽窃难以界定。不过,生成式人工智能作为技术工具,即便可被学理解释为类人性学术主体,仍难以等同于“他人”所指称的“生物人与社会人”概念,因此就字面解释而言,无法将使用生成式人工智能行为径自解释为学术不端行为的剽窃。
唯一可能解释为剽窃的路径是,将生成式人工智能解释为特定法人或自然人的服务或产品,从而将科研人员使用生成式人工智能生成学术内容,解释为剽窃特定法人或自然人的成果。但实践中,生成式人工智能等人工智能软件运营商通常在其服务条款中明确,用户使用人工智能时输入与输出内容的所有权及相关权益,均授予用户。因此,科研人员使用生成式人工智能生成内容通常具有合法权源,难谓不正当手段窃取,因此不可认定为剽窃自生成式人工智能。但是,如若人工智能服务提供商未在服务合同中明确用户对生成内容具有所有权,而仅赋予查阅权,此时科研人员如若强行将生成内容使用于学术成果中且未清楚显著标注时,便可能构成“剽窃”学术不端行为。《科学》杂志便明确表示,使用生成式人工智能生成的文字,构成对生成式人工智能的剽窃。[6]
2.1.2 是否构成剽窃他人学术成果
剽窃他人学术成果中的“他人”,意指其他自然人。由于生成式人工智能生成学术内容是以数据训练为基础的,而用于训练的数据既可能是公共领域的知识与数据,也可能是他人的观点、数据与作品等,这便成为使用生成式人工智能构成剽窃的技术源头。使用生成式人工智能构成剽窃,包含两种情形。
第一种情形是,未取得非生成式人工智能用户的授权,也未满足适当引用的合理使用要件,擅自使用非生成式人工智能用户的观点、数据与作品等,构成剽窃。2023年美国作者协会与17名作家联名起诉Open AI未经授权使用版权作品训练其大语言模型ChatGPT,同时OpenAI的ChatGPT输出内容与版权作品实质性相似,属于复制型剽窃版权侵权。[7]
第二种情形是,未经其他生成式人工智能用户授权,亦未合理标注引用,擅自使用其他生成式人工智能用户的输入内容,构成剽窃。由于用户在使用生成式人工智能时,用户的输入会被生成式人工智能实时复制记录,作为其模型训练的“养料”,成为后续其他用户使用生成式人工智能输出内容的组成部分。由于“算法黑箱”的存在,用户使用生成式人工智能生成内容时,难以知晓特定生成内容是其他生成式人工智能用户的输入内容。由此,使用生成式人工智能生成学术内容可能构成对其他生成式人工智能用户输入内容的剽窃。
2.2 使用生成式人工智能构成伪造
生成式人工智能输出内容与真实信息的异质性“信息失真”,可能是“偏差”数据“喂养”训练的结果,也可能是“虚拟”数据“喂养”训练的结果。[8]前者是指使用客观世界信息化的真实数据集进行训练;后者是指使用人工智能合成的虚拟数据集训练生成式人工智能。因此,使用生成式人工智能生成学术内容是否构成“伪造”可分为两种情形讨论。
2.2.1 “偏差”数据喂养引致伪造
当使用“偏差”真实数据训练时,由于归纳逻辑下的“偏差”数据集的小样本,难以反映真实世界的全貌,生成式人工智能会生成“以偏概全”“指鹿为马”的内容。此种与真实世界部分不对应的偏差信息,可谓之“错误信息”。
由于生成式人工智能生成的错误学术内容与真实学术信息不符,并非科研人员主观故意虚构或编造所致,因此具有补正的主观可能性与客观可行性。只要科研人员对生成式人工智能生成学术内容进行审慎校对后予以查明并改正,便可发现并消弭该学术内容中的错误。但如若科研人员使用生成式人工智能生成的错误学术内容而不察,或明知该错误学术内容而不改正,径自作为终端学术内容而进入投稿阶段,便具有主观意志与客观行为层面的可归责性。因此,当生成式人工智能生成“以偏概全”或“指鹿为马”的错误学术内容时,科研人员未有效查明并改正,而是径自将错误学术内容纳入终端学术成果予以发表,可能构成学术不端行为中的伪造。
2.2.2 “虚拟”数据喂养引致伪造
当使用“虚拟”合成数据训练时,由于数据本身是基于特定场景需求,通过逻辑建构后予以合成,与真实世界的事物并不完全对应,因此生成式人工智能可能会“无中生有”“胡说八道”式生成虚假内容。[9]此种与真实世界不严格对应的虚假内容,可谓之“虚假信息”。
由于训练数据集的非公开性与算法“黑箱”的存在,科研人员无从知晓生成式人工智能是否使用“虚拟”数据进行训练,也就无法确定生成内容的非“虚假”性。因此,科研人员在使用生成式人工智能生成的学术内容时,便需要谨慎核查。如若科研人员未秉持谨慎态度认真核查生成式人工智能生成学术内容是否为虚假信息,而是径自将虚假信息使用于终端学术内容之中;或者明知生成式人工智能生成学术内容为虚假信息,仍在终端学术内容中予以使用,那么科研人员对终端学术内容使用虚假内容,主观意图与客观行为上均具有可责难性。由于虚假信息的本质是虚构或编造的信息,因此使用生成式人工智能生成的虚假信息作为终端学术内容并进行投稿发表,可能构成学术不端行为的伪造。
2.3 使用生成式人工智能构成代写
代写是指由非论文署名者代替署名者撰写学术内容。《办法》中明确规定,由他人代写论文是学术不端行为。从文义解释可知,如欲构成学术不端行为之代写,主体方面为两人以上;主观方面为主体之间形成代替撰写论文的共谋故意;客体方面为论文等学术内容;客观方面为非论文创造者在论文上署名,而论文实际撰写者未署名;同时,代写的成立并不需要主体之间存在现实利益输送,即便是基于好意施惠所为的代写,亦可构成学术不端意义之代写。
2.3.1 他人使用生成式人工智能构成代写
前生成式人工智能时期,代写涉及主体均为自然人,即便一方或双方表面上为法人或其他组织,但其背后实际执行主体仍为自然人,因此学术不端行为之代写的表述皆为“他人”代写,此种表述转述为“其他自然人代写”亦难谓谬误。但生成式人工智能出现之后,除自然人亲自实施代写情形外,还产生“他人使用生成式人工智能”的特殊代写情形。
就“他人使用生成式人工智能”而言,虽然其中牵涉生成式人工智能这一所谓“学术研究变革者”,但无论人们将生成式人工智能视同为工具,如“笔”与“WORD”软件之于人;还是将生成式人工智能视为类人性主体,类比为法人或新设为电子人,“他人使用生成式人工智能为代写”均能够符合传统代写的构成要件,因此毫无争议可被视为学术不端意义的代写。
2.3.2 署名者使用生成式人工智能构成代写
就“署名者使用生成式人工智能”而言,由于涉及的自然人主体仅为署名者一方,另一方为生成式人工智能,因此难以匹配代写主体均为自然人之要求,同样单个自然人亦无从形成需要两人以上方可成立的共谋故意。此时,“非人”生成式人工智能能否构成代写之“他人”便会存疑。如若严格按照文义解释而言,生成式人工智能当然不属于“人”的自然范畴。如若扩张解释“他人”,将“法人与其他组织”囊括其中,生成式人工智能仍与此时的“他人”概念存在悖反。因为法人与其他组织代写的本质,仍是自然人实施撰写,学术成果的实际创作者是自然人,而使用生成式人工智能时的实际创作者是生成式人工智能本身,自然人并未直接实施创作行为,因此难以归入法人或其他组织代写类型。由于缺乏自然人主体要素,因此“署名者使用生成式人工智能”无法归入《办法》指称的代写。
但“署名者使用生成式人工智能”时所生成的学术内容是生成式人工智能自动生成,确非署名者自身学术能力产生的成果,该学术内容与署名者之间仅具备间接联系。“署名者使用生成式人工智能”,除却主体的“非人”属性外,基本符合代写构成要件。如若放任署名者将其作为自身的学术成果并对外进行发表,会使得社会成员误认为该学术成果为署名者的学术能力与学术贡献的体现,从而严重违背学术伦理与学术道德。正如学者所述,技术发展已突破传统代写的概念范畴,为应对技术的发展,应当将科研人员擅自使用人工智能生成的学术内容,认定为学术不端意义的代写。[10]
署名资格及其顺序,关乎对署名者在学术成果形成过程中的贡献程度的认可,以及署名者对该学术成果的伦理与法律责任承担的自主认领。而不当署名则是署名资格及其顺序,违背实质性贡献度规则,错配署名主体与责任。总体而言,不当署名包含两个维度:署名资格使用不当与署名排序使用不当。
就署名资格使用不当而言,将生成式人工智能列为学术成果的作者,将被认定为不当署名。当然,此种观点存在成立前提:生成式人工智能不具备著作权法意义的作者资格。纵观世界各国法域的实在法规则,无论采取主体官能说,抑或秉持客观能力说,无论是否承认计算机独立生成成果的作品适格性,均只认可自然人、法人或非法人组织作为著作权法意义的作者。因为建立在“人类中心主义”之上,为激励人类创新、促进人的自我实现、推动社会经济发展的著作权法规则,无法将“非人”生成式人工智能视为作者。
就署名顺序使用不当而言,使用生成式人工智能生成学术内容构成署名顺序不当,不仅需要生成式人工智能具备合理署名资格作为前提,而且该署名顺序不当必须是因生成式人工智能插入署名序列导致的贡献度排列混乱,否则不可谓之署名顺序不当。
由于各国实在法均不承认人工智能的作者资格,所以生成式人工智能不可以在学术成果中合理署名。因此,使用生成式人工智能生成学术内容构成署名顺序不当,缺乏成立的前提条件。即便实践中存在将生成式人工智能置入作者板块进行署名,从而使得署名顺序紊乱的情况,其实质仍不是署名顺序问题,而是署名资格问题。毕竟一旦否认生成式人工智能的署名资格,将其排除在署名位次之中,署名顺序问题便迎刃而解。
3 使用生成式人工智能的学术出版伦理困境的法律治理
3.1 构建生成式人工智能使用的“三四三”结构软法义务约束
图1
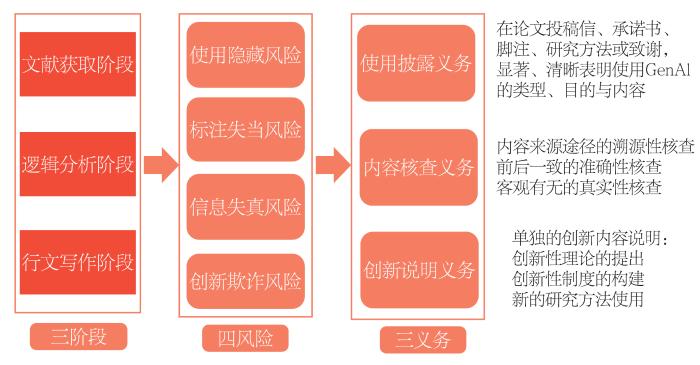
首先,就使用隐藏风险而言,设置使用披露义务。针对科研人员可能隐藏生成式人工智能使用行为,从而诱致使用隐藏风险的情况,应当要求科研人员投稿时承担使用披露义务。换言之,如若科研人员在学术科研活动中使用生成式人工智能,那么其应当在终端学术成果投稿出版时以合适方式表明生成式人工智能的使用方式与类型。合适方式表明包括但不限于在投稿信、承诺书、论文脚注、研究方法或致谢部分,显著、清晰与明确地表明生成式人工智能在学术内容生成中使用的目的、所有提示词与生成的内容、生成式人工智能的名称、版本与类型等。
其次,就信息失真风险而言,设置内容核查义务。针对科研人员未合理审查生成式人工智能生成内容的真实性和准确性,从而诱致信息失真风险的情况,应当要求科研人员投稿出版时承担内容核查义务。换言之,科研人员在学术科研活动中使用生成式人工智能生成学术内容的,在披露生成式人工智能使用情况的基础上,应对生成式人工智能生成的学术内容进行仔细的核查,包括但不限于内容来源途径的溯源性核查、内容前后一致的准确性核查、内容客观有无的真实性核查,同时向出版商等社会主体以承诺或声明的方式明确报告核查方式与内容,并对学术内容与报告内容的真实性、准确性、可靠性负责。
最后,就创新欺诈风险而言,设置创新说明义务。针对科研人员可能未躬身或主要参与假设验证、数据处理与逻辑分析,以及未从事或未主要参与学术内容的具体写作,而是通过提示词引导生成式人工智能生成主要或全部学术内容,并径自冠以己名,从而诱致创新欺诈风险的情况,应当要求科研人员投稿出版时承担创新说明义务。换言之,科研人员应当在向出版商或其他主体提供学术内容时,明确地说明科研人员自身在学术内容生成时所作出的创新性贡献,包括但不限于创新性理论的提出、创新性制度的构建与新的研究方法使用等,将科研人员的智力贡献与生成式人工智能生成内容予以区别,从而准确且合理评价学术内容中科研人员的智力贡献与学术价值。
3.2 合理使用生成式人工智能的反向检测工具
学术出版活动需要保持诚信和透明,采取严厉措施保证学术诚信和学术质量成为学术界共识。作为学术诚信和学术质量的有效维护措施,技术性检测工具得到学术界的认可,如中国知网的学术不端文献检测系统等。然而,传统技术性检测工具的技术理性立足于是否复制或剽窃自他人,是一种相似性检测。此种相似性检测逻辑,仅能确定学术成果是否复制或剽窃自他人,却难以有效检测学术成果是否以及多大程度是生成式人工智能生成内容。所以,传统技术性检测工具难以有效契合生成式人工智能场景下的检测需求。同时,通过“图灵测试”的生成式人工智能,其生成的内容主题相关性高、逻辑性强且符合学术论文逻辑结构,仅依靠人类专家进行审查识别,亦难以胜任检测任务。因此,生成式人工智能生成内容的技术性检测,应使用专门的生成式人工智能反向检测工具。[14]
但实践中存在的生成式人工智能反向检测工具,基本立足于词语概率与语言模型困惑度(复杂度)检测逻辑,这就导致结构简单与常用(随机性不强)的文本内容容易被视为是生成式人工智能生成。2023年,斯坦福大学对人工智能反向检测工具的研究便表明,误判率高的托福文章在词语选择与语言结构等方面的复杂度上明显低于其他文章。[15]因此,通过复杂度来判定内容是人类还是生成式人工智能生成,在全面性、严谨性方面存在一定的缺陷。这是因为反向检测工具仅能识别重复内容,却很难识别重复内容的性质。所以生成式人工智能反向检测工具的检测结果,仅是学术成果是否为生成式人工智能生成内容的判定参考,而不是终局的决定性“判决”。
在出现对于科研人员不利的特定检测结果时,应当赋予科研人员一项程序性权利,即赋予科研人员异议权,允许科研人员提供证据反驳检测结果。我国《著作权法》第二十四条规定的著作权合理使用制度,赋予人们在介绍、评论作品或说明问题时,可以适当引用他人已发表的作品。因此,即便生成式人工智能反向检测后的结果显示复制比超过一定比例,但是如若复制的内容属于合理引用,便不属于学术不端。同时,我国《著作权法》第五条规定,官方文件、单纯事实消息、公式等不受著作权法保护,任何人均可以使用。因此,如若反向检测结果显示的剽窃内容,包含大量官方文件、单纯事实消息等公有领域知识,即便检测结果的复制比极高,也不应认定为学术不端。
3.3 完善学术不端认定规则和配套的处罚机制
当前,我国《处理办法》第三条与《行为办法》第二十七条均规定了剽窃、伪造、代写、不当署名等学术不端行为;另外,行业标准《学术出版规范》中进一步界定了各种学术不端行为的概念与行为表现。但此类规定仅适用于前生成式人工智能时代利用机械科研工具的自然人学术不端行为,而无法有效规范类人性学术主体生成式人工智能在学术科研领域内的使用。针对生成式人工智能对学术科研领域内学术诚信的冲击,2023年我国《学位法(草案)》中第三十三条明确将人工智能代写纳入学术不端行为。然而,令人遗憾的是,2024年我国正式通过的《学位法》第三十七条将“人工智能代写”予以删除,如此规定无助于规范生成式人工智能等人工智能技术在学术科研活动中的使用。为规范使用生成式人工智能学术不端行为,在法律条文中应采取“列举+概括”的立法模式,实现类型化条款与抽象原则条款的相结合。
具体而言,对于用户协议未授予科研人员所有权的使用情形,擅自使用人工智能生成学术内容侵犯他人研究成果,触发创新欺诈风险,违反创新说明义务的,可规定为学术不端的剽窃行为;对生成式人工智能生成的错误与虚假学术内容,未加审查便径自予以使用,触发信息失真风险,违反内容核查义务的,可规定为学术不端的伪造行为;对于用户协议授予科研人员所有权,但未标识生成式人工智能生成学术内容,触发使用隐藏风险,违反使用披露义务的,可规定为学术不端的代写行为;对于擅自将生成式人工智能列为作者或者合作作者情形,触发标注失当风险,违反内容核查义务的,可规定为学术不端的不当署名行为。上述四种学术不端行为中,由于不当署名行为已标明生成式人工智能的使用,对学术诚信与学术出版伦理冲击较小,因此,可以免于法律制裁而采取行业规制,如要求科研人员更正署名或要求其撤稿;但使用生成式人工智能生成学术内容构成剽窃、伪造与代写等行为时,由于会严重侵蚀科研诚信的底座,破坏学术出版伦理,因此应当严厉处罚。
处罚机制采取行业软法与法律硬法有效协同建构。其中行业软法处罚,包括出版机构要求撤稿、道歉、拉入科研失信黑名单;学术组织可开除学术不端人员的学术会员资格,剥夺其学术职衔与荣誉,并公开谴责。法律硬法处罚,包括按照《学位法》可撤销相关科研人员的学位,禁止其3年内再次申请学位。科研人员属于在读全日制学生的,由所在学校与学位授予单位根据情形的严重程度可给予开除学籍处分;科研人员属于非全日制学生的,由学位授予单位根据情况可给予纪律处分,并向其工作单位通报,情节严重且社会影响恶劣的,可开除学籍。对于高等院校的教职人员,可根据情形给予通报批评、纪律处分、取消研究生招生资格等相应处罚措施;学术不端社会影响恶劣的,可解除劳动关系。对学术不端认定规则与处罚规则的进一步完善,可有效预防与规制学术科研领域生成式人工智能的不当利用行为。
4 结语
正如史蒂芬·霍金所言,“人工智能的成功创造可能是人类历史上最大的事件。不幸的是,如果我们不学会如何避免风险,这也可能是最后一次”。[16]对于人工智能的类理性发展引致的风险,应当采取有效措施预防与控制。在促进生成式人工智能广泛使用的基础上,约束学术不端风险的现实化,方可促进科学进步与社会发展。
参考文献
Scientific sleuths spot dishonest ChatGPT use in papers
[EB/OL].(
Utilization of E-commerce for fossil fuels allocation and green recovery
[J].
Famous authors' lawsuit against ChatGPT developer gets underway
[EB/OL].(
New recommendations of the International Committee of Medical Journal Editors:use of artificial intelligence
[J].
GPT detectors are biased against non-native English writers
[J/OL].(

{kind=link}
{kind=link}