information extraction in editorial setting. A Tale of PDFs
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Layout aware semantic element extraction for sustainable science & technology decision support
1
2022
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Unfolding the structure of a document using deep learning
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Link Prediction using numerical weights for knowledge graph completion within the scholarly domain
1
2021
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Clustering semantic predicates in the open research knowledge graph
1
2022
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Semantic representation of scientific publications
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Semantic publication of agricultural scientific literature using property graphs
1
2020
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
OpenBiodiv:a Knowledge graph for literature-extracted linked open data in biodiversity science
1
2019
... 开放科学背景下,跨学科研究是解决当今众多纷杂社会问题的重要手段.如何存储、管理并集成这些分散学科下的数据,实现领域性数据融合已经成为研究热点.借助本体模型,这些特定领域和学科的研究人员开始致力于多领域融合的知识图谱构建,以更精准地捕捉知识的结构和语义内涵.这类研究涉及生物多样性科学、复合材料科学、生物医学信息学等大量跨学科的问题场景,为学科之间的交叉合作和创新研究提供了基础的技术和知识支撑.[53,54,55,56] ...
NanoMine:A knowledge graph for nanocomposite materials science
1
2020
... 开放科学背景下,跨学科研究是解决当今众多纷杂社会问题的重要手段.如何存储、管理并集成这些分散学科下的数据,实现领域性数据融合已经成为研究热点.借助本体模型,这些特定领域和学科的研究人员开始致力于多领域融合的知识图谱构建,以更精准地捕捉知识的结构和语义内涵.这类研究涉及生物多样性科学、复合材料科学、生物医学信息学等大量跨学科的问题场景,为学科之间的交叉合作和创新研究提供了基础的技术和知识支撑.[53,54,55,56] ...
Rare disease-based scientific annotation knowledge graph
1
2022
... 开放科学背景下,跨学科研究是解决当今众多纷杂社会问题的重要手段.如何存储、管理并集成这些分散学科下的数据,实现领域性数据融合已经成为研究热点.借助本体模型,这些特定领域和学科的研究人员开始致力于多领域融合的知识图谱构建,以更精准地捕捉知识的结构和语义内涵.这类研究涉及生物多样性科学、复合材料科学、生物医学信息学等大量跨学科的问题场景,为学科之间的交叉合作和创新研究提供了基础的技术和知识支撑.[53,54,55,56] ...
AIDA:A knowledge graph about research dynamics in academia and industry
1
2021
... 开放科学背景下,跨学科研究是解决当今众多纷杂社会问题的重要手段.如何存储、管理并集成这些分散学科下的数据,实现领域性数据融合已经成为研究热点.借助本体模型,这些特定领域和学科的研究人员开始致力于多领域融合的知识图谱构建,以更精准地捕捉知识的结构和语义内涵.这类研究涉及生物多样性科学、复合材料科学、生物医学信息学等大量跨学科的问题场景,为学科之间的交叉合作和创新研究提供了基础的技术和知识支撑.[53,54,55,56] ...
1
2020
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Semantic publishing:the coming revolution in scientific journal publishing
1
2009
... 语义出版作为数字出版的高级形态,其概念最早由Shotton于2009年提出[1],目前已经成为学术出版领域的主流出版形式.利用语义技术实现对文献内容的语义增强是实现智能化出版和知识服务的重要基础. ...
延续与突破:2017年语义出版研究与实践回顾
2
2018
... 伴随人工智能技术与语义技术的普及与应用,语义出版领域的研究在围绕文献内容的结构化、关联化、语义化等方面均获得了重要进展.新兴的科学知识图谱和开放关联数据成为语义出版物的常见表现形式,语义出版开始向知识网络建设稳步迈进[2].语义出版物数量的快速增长为其在科学发现和科学交流的深入应用带来新的机遇. ...
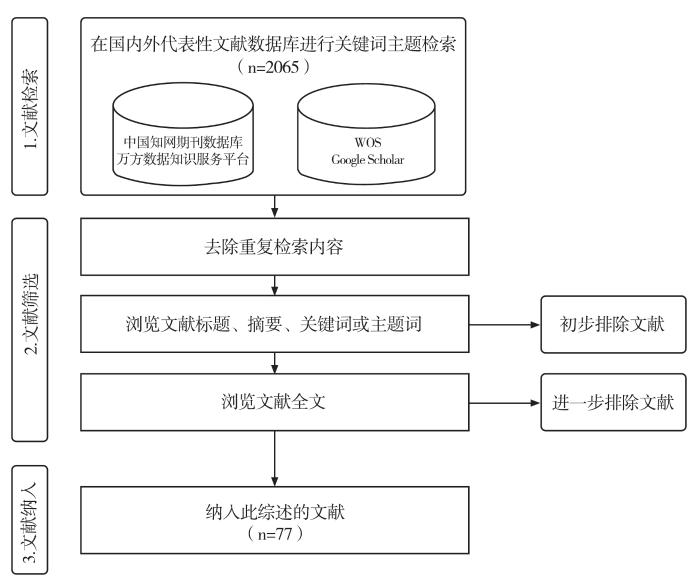
... (1)文献检索的对象为国内外语义出版相关的可检索文献.考虑到2018年以前已有相关的综述文章[2,3],本研究将文献检索的时间范围设置为2019—2022年.首先,以“主题”字段值为“语义出版”“语义出版物”“纳米出版”“纳米出版物”“微型出版”“微型出版物”“增强出版”“增强出版物”在中国知网期刊数据库和万方数据知识服务平台上检索.然后以“主题”字段值为“semantic publishing”“semantic publication”“micropublication”“micropublishing”“nanopublication”“enhanced publishing”“enhanced publishcation”在Web of Science核心合集数据库和Google学术搜索中检索文献,共计得到2 065篇中、外文文献. ...
国内外语义出版理论研究述评
1
2017
... (1)文献检索的对象为国内外语义出版相关的可检索文献.考虑到2018年以前已有相关的综述文章[2,3],本研究将文献检索的时间范围设置为2019—2022年.首先,以“主题”字段值为“语义出版”“语义出版物”“纳米出版”“纳米出版物”“微型出版”“微型出版物”“增强出版”“增强出版物”在中国知网期刊数据库和万方数据知识服务平台上检索.然后以“主题”字段值为“semantic publishing”“semantic publication”“micropublication”“micropublishing”“nanopublication”“enhanced publishing”“enhanced publishcation”在Web of Science核心合集数据库和Google学术搜索中检索文献,共计得到2 065篇中、外文文献. ...
CCRO:citation’s Context & Reasons Ontology
1
2019
... 当前通用领域出版物内容本体建设的侧重点是从引用动机及情感倾向、论证角度来揭示科学论文中的隐性语义.作者在引用先前研究时,往往会在上下文中表达其观点态度.揭示引用动机及情感倾向有助于读者深入把握作者的引用意图,为科技文献的影响力评估、智能推荐等研究提供参考.例如,CCRO本体将科学论文间互相引用的原因简化为8个不相交的方向[4],OpenCitations本体通过规范学术引用关系来追踪学者思想观点的演变.[5]科学论文内蕴含的论证结构体现了作者的逻辑推理过程.王晓光等关注科学论文内隐藏的重要科学观点、结论以及论证过程,在国内首次提出论证本体SAO.[6]曲佳彬等从语句、实体及语境3个层面构建科学论文论证结构本体,更全面、更细粒度地揭示了论文的论证结构.[7]结合论证理论和引用关系,本体EVI基于文献数据为用户透明地生成和扩展证据图.[8] ...
The open citations data model
1
2020
... 当前通用领域出版物内容本体建设的侧重点是从引用动机及情感倾向、论证角度来揭示科学论文中的隐性语义.作者在引用先前研究时,往往会在上下文中表达其观点态度.揭示引用动机及情感倾向有助于读者深入把握作者的引用意图,为科技文献的影响力评估、智能推荐等研究提供参考.例如,CCRO本体将科学论文间互相引用的原因简化为8个不相交的方向[4],OpenCitations本体通过规范学术引用关系来追踪学者思想观点的演变.[5]科学论文内蕴含的论证结构体现了作者的逻辑推理过程.王晓光等关注科学论文内隐藏的重要科学观点、结论以及论证过程,在国内首次提出论证本体SAO.[6]曲佳彬等从语句、实体及语境3个层面构建科学论文论证结构本体,更全面、更细粒度地揭示了论文的论证结构.[7]结合论证理论和引用关系,本体EVI基于文献数据为用户透明地生成和扩展证据图.[8] ...
科学论文论证本体设计与标注实验
1
2020
... 当前通用领域出版物内容本体建设的侧重点是从引用动机及情感倾向、论证角度来揭示科学论文中的隐性语义.作者在引用先前研究时,往往会在上下文中表达其观点态度.揭示引用动机及情感倾向有助于读者深入把握作者的引用意图,为科技文献的影响力评估、智能推荐等研究提供参考.例如,CCRO本体将科学论文间互相引用的原因简化为8个不相交的方向[4],OpenCitations本体通过规范学术引用关系来追踪学者思想观点的演变.[5]科学论文内蕴含的论证结构体现了作者的逻辑推理过程.王晓光等关注科学论文内隐藏的重要科学观点、结论以及论证过程,在国内首次提出论证本体SAO.[6]曲佳彬等从语句、实体及语境3个层面构建科学论文论证结构本体,更全面、更细粒度地揭示了论文的论证结构.[7]结合论证理论和引用关系,本体EVI基于文献数据为用户透明地生成和扩展证据图.[8] ...
语义出版驱动的科学论文论证结构语义建模研究
1
2021
... 当前通用领域出版物内容本体建设的侧重点是从引用动机及情感倾向、论证角度来揭示科学论文中的隐性语义.作者在引用先前研究时,往往会在上下文中表达其观点态度.揭示引用动机及情感倾向有助于读者深入把握作者的引用意图,为科技文献的影响力评估、智能推荐等研究提供参考.例如,CCRO本体将科学论文间互相引用的原因简化为8个不相交的方向[4],OpenCitations本体通过规范学术引用关系来追踪学者思想观点的演变.[5]科学论文内蕴含的论证结构体现了作者的逻辑推理过程.王晓光等关注科学论文内隐藏的重要科学观点、结论以及论证过程,在国内首次提出论证本体SAO.[6]曲佳彬等从语句、实体及语境3个层面构建科学论文论证结构本体,更全面、更细粒度地揭示了论文的论证结构.[7]结合论证理论和引用关系,本体EVI基于文献数据为用户透明地生成和扩展证据图.[8] ...
Evidence graphs:supporting transparent and FAIR computation,with defeasible reasoning on data,methods,and results
1
2021
... 当前通用领域出版物内容本体建设的侧重点是从引用动机及情感倾向、论证角度来揭示科学论文中的隐性语义.作者在引用先前研究时,往往会在上下文中表达其观点态度.揭示引用动机及情感倾向有助于读者深入把握作者的引用意图,为科技文献的影响力评估、智能推荐等研究提供参考.例如,CCRO本体将科学论文间互相引用的原因简化为8个不相交的方向[4],OpenCitations本体通过规范学术引用关系来追踪学者思想观点的演变.[5]科学论文内蕴含的论证结构体现了作者的逻辑推理过程.王晓光等关注科学论文内隐藏的重要科学观点、结论以及论证过程,在国内首次提出论证本体SAO.[6]曲佳彬等从语句、实体及语境3个层面构建科学论文论证结构本体,更全面、更细粒度地揭示了论文的论证结构.[7]结合论证理论和引用关系,本体EVI基于文献数据为用户透明地生成和扩展证据图.[8] ...
Towards the semantic formalization of science
1
2020
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
SemSur:a core ontology for the semantic representation of research findings
1
2018
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
Semantic representation of physics research data
1
2020
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
Ontology design for pharmaceutical research outcomes
1
2020
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
FIDEO:food interactions with drugs evidence ontology
1
2020
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
C-tro:an ontology for summarization and aggregation of the level of evidence in clinical trials
1
2019
... 出版物内容本体构建的另一个重要方向是描述具体学科领域内文献资源中的知识实体关系,以实现该领域内的知识聚合与知识搜索.其中,最具代表性的科学知识图谱本体套件SKGO,对现代科学各个领域的研究成果实现建模,以结构化的方式表示研究问题,构建知识库并辅助生成领域知识图谱.[9]SKGO包括五个领域本体,分别是计算机科学(SemSur)、化学(ChemSci)、物理(PhySci)、牙科(DentSci)以及药剂学(Pharmsci).[10,11,12]除此之外,基于跨学科、跨研究科学文章构建的本体也体现出语义技术在特定领域知识组织上的应用,例如食品药物相互作用证据本体FIDEO [13]、临床试验证据本体C-TrO [14]等. ...
中文科技期刊语义出版态势分析
1
2019
... 语义环境下,科技文献内容的语义组织粒度进一步细化,而由众包或本体模型主导的科技文献内容结构化与语义化成本较高.在此背景下,学者们正密切关注语义技术与出版流程的有机整合.出版对象从传统出版物至结构化“知识单元”的形式转变,能够有效促进信息的再利用和按需重组,为构建可持续知识基础设施带来机遇.[15,16] ...
Where the rubber meets the road:identifying integration points for semantic publishing in existing scholarly practice
1
... 语义环境下,科技文献内容的语义组织粒度进一步细化,而由众包或本体模型主导的科技文献内容结构化与语义化成本较高.在此背景下,学者们正密切关注语义技术与出版流程的有机整合.出版对象从传统出版物至结构化“知识单元”的形式转变,能够有效促进信息的再利用和按需重组,为构建可持续知识基础设施带来机遇.[15,16] ...
科技期刊语义出版的学术不端防范功能的实现
1
2019
... 面向语义出版的可视化编辑工具的开发,将为学者和编辑人员参与语义出版流程提供新的可能,尤其是在科技文献的创作和审稿发布阶段.[17]目前已有研究将CCRO本体融入LaTeX编辑工具以支撑带有引用原因信息的文献创作和发布.[18]RDFtex框架集成了SciKG与LaTeX编辑工具,旨在缩小传统出版物与RDF之间的距离.[19]结合Fidus Writer学术编辑器和OJS评审管理系统支持的同行评审工作流程,能够生成带有注释且内容机器可读的数据.[20]STM(Smart Topic Miner)是辅助Springer Nature等科技期刊编辑团队的常见效率工具,用来进行学术会议论文的研究主题自动归类,并有望进一步实现科学出版物内容高质量元数据的自动生成.[21] ...
An NLP-based citation reason analysis using CCRO
1
2021
... 面向语义出版的可视化编辑工具的开发,将为学者和编辑人员参与语义出版流程提供新的可能,尤其是在科技文献的创作和审稿发布阶段.[17]目前已有研究将CCRO本体融入LaTeX编辑工具以支撑带有引用原因信息的文献创作和发布.[18]RDFtex框架集成了SciKG与LaTeX编辑工具,旨在缩小传统出版物与RDF之间的距离.[19]结合Fidus Writer学术编辑器和OJS评审管理系统支持的同行评审工作流程,能够生成带有注释且内容机器可读的数据.[20]STM(Smart Topic Miner)是辅助Springer Nature等科技期刊编辑团队的常见效率工具,用来进行学术会议论文的研究主题自动归类,并有望进一步实现科学出版物内容高质量元数据的自动生成.[21] ...
RDFtex:Knowledge exchange between LaTeX-Based research publications and scientific knowledge graphs
1
2022
... 面向语义出版的可视化编辑工具的开发,将为学者和编辑人员参与语义出版流程提供新的可能,尤其是在科技文献的创作和审稿发布阶段.[17]目前已有研究将CCRO本体融入LaTeX编辑工具以支撑带有引用原因信息的文献创作和发布.[18]RDFtex框架集成了SciKG与LaTeX编辑工具,旨在缩小传统出版物与RDF之间的距离.[19]结合Fidus Writer学术编辑器和OJS评审管理系统支持的同行评审工作流程,能够生成带有注释且内容机器可读的数据.[20]STM(Smart Topic Miner)是辅助Springer Nature等科技期刊编辑团队的常见效率工具,用来进行学术会议论文的研究主题自动归类,并有望进一步实现科学出版物内容高质量元数据的自动生成.[21] ...
Opening and reusing transparent peer reviews with automatic article annotation
1
2019
... 面向语义出版的可视化编辑工具的开发,将为学者和编辑人员参与语义出版流程提供新的可能,尤其是在科技文献的创作和审稿发布阶段.[17]目前已有研究将CCRO本体融入LaTeX编辑工具以支撑带有引用原因信息的文献创作和发布.[18]RDFtex框架集成了SciKG与LaTeX编辑工具,旨在缩小传统出版物与RDF之间的距离.[19]结合Fidus Writer学术编辑器和OJS评审管理系统支持的同行评审工作流程,能够生成带有注释且内容机器可读的数据.[20]STM(Smart Topic Miner)是辅助Springer Nature等科技期刊编辑团队的常见效率工具,用来进行学术会议论文的研究主题自动归类,并有望进一步实现科学出版物内容高质量元数据的自动生成.[21] ...
Improving editorial workflow and metadata quality at springer nature
1
2019
... 面向语义出版的可视化编辑工具的开发,将为学者和编辑人员参与语义出版流程提供新的可能,尤其是在科技文献的创作和审稿发布阶段.[17]目前已有研究将CCRO本体融入LaTeX编辑工具以支撑带有引用原因信息的文献创作和发布.[18]RDFtex框架集成了SciKG与LaTeX编辑工具,旨在缩小传统出版物与RDF之间的距离.[19]结合Fidus Writer学术编辑器和OJS评审管理系统支持的同行评审工作流程,能够生成带有注释且内容机器可读的数据.[20]STM(Smart Topic Miner)是辅助Springer Nature等科技期刊编辑团队的常见效率工具,用来进行学术会议论文的研究主题自动归类,并有望进一步实现科学出版物内容高质量元数据的自动生成.[21] ...
可计算医学知识的基本概念与实现路径
1
2021
... 基于上述研究,学者们的探索还在持续向语义出版工作流的各个后续环节延展,以向广大科研工作者提供更加智能化的知识服务.例如,K-Grid-China从内容组织语义化的医学期刊文献中提取可计算医学知识并应用于医疗实践.[22]Augustus等设计了具备实时更新计算结果功能的发布系统,旨在探索科学论文产生持久价值的有效方式.[23]此外,出版流程的语义化增强在学者们创作前期的知识发现阶段也有所表现.例如,ComplEx模型能够帮助领域专家识别新的研究假设,促进自动化的科学发现.[24] ...
Enabling live publication
1
2022
... 基于上述研究,学者们的探索还在持续向语义出版工作流的各个后续环节延展,以向广大科研工作者提供更加智能化的知识服务.例如,K-Grid-China从内容组织语义化的医学期刊文献中提取可计算医学知识并应用于医疗实践.[22]Augustus等设计了具备实时更新计算结果功能的发布系统,旨在探索科学论文产生持久价值的有效方式.[23]此外,出版流程的语义化增强在学者们创作前期的知识发现阶段也有所表现.例如,ComplEx模型能够帮助领域专家识别新的研究假设,促进自动化的科学发现.[24] ...
Discovering research hypotheses in social science using knowledge graph embeddings
1
2021
... 基于上述研究,学者们的探索还在持续向语义出版工作流的各个后续环节延展,以向广大科研工作者提供更加智能化的知识服务.例如,K-Grid-China从内容组织语义化的医学期刊文献中提取可计算医学知识并应用于医疗实践.[22]Augustus等设计了具备实时更新计算结果功能的发布系统,旨在探索科学论文产生持久价值的有效方式.[23]此外,出版流程的语义化增强在学者们创作前期的知识发现阶段也有所表现.例如,ComplEx模型能够帮助领域专家识别新的研究假设,促进自动化的科学发现.[24] ...
结论型知识元语义描述模型探析
1
2020
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
基于纳米出版物的中文学位论文语义组织研究
1
2021
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
Representing physician suicide claims as nanopublications:proof-of-concept study creating claim networks
1
2022
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
Using nanopublications to detect and explain contradictory research claims
1
2021
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
A unified nanopublication model for effective and user-friendly access to the elements of scientific publishing
1
2020
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
A nano(publication)approach towards big data in biodiversity
1
2021
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
GAP:enhancing semantic interoperability of genomic datasets and provenance through nanopublications
1
2022
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
Provenance for linguistic corpora through nanopublications
1
2020
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
Data quality issues in current nanopublications
1
2019
... 到目前为止,纳米出版物被应用于多个学术领域的知识表示.一方面,纳米出版物被应用于描述学术论文中的结论型知识元[25]、科学论断[26,27]、研究主张出处[28]等.基于纳米出版物实现对同行评审意见的语义表达,还可以为出版审查提供可靠的数据依据,为科学交流中的同行评审活动提供便捷的知识服务.[29,30]另一方面,纳米出版物的机器可读性对实现学术界的各类数据重用存在很大助益,例如生物医学领域的基因组数据集[31]和社会研究领域的语言类数据集等[32].需要注意的是,由于自然语言的复杂性,利用NLP技术抽取论断生成纳米出版物还需要更多技术层面上的探索,创建高质量的纳米出版物需要一个更加统一、详细、准确的建模指南.[33] ...
Semantic micro-contributions with decentralized nanopublication services
1
2021
... 纳米出版物的可视化系统设计和开发,正在试图推进以人类易理解的形式实现纳米出版物的发布、检索、浏览、获取与引用.具体来说,Nanobench利用分散式服务网络,帮助用户通过界面交互操作发布小型关联数据语句,同时也为用户查询知识提供了更加便捷且可靠的途径.[34]NanoWeb系统提供了能够访问、探索和重用开放纳米出版物的可视化接口,并支持链接到纳米出版物的出处论文和数据库.[35]纳米出版物引用框架Nanocitation为纳米出版物缺少引用标准提供解决方案,并开发公开可用的WebApp,以便用户自动创建引文文本片段以及机器可读的纳米出版物引用.[36] ...
Search,access,and explore life science nanopublications on the Web
1
2021
... 纳米出版物的可视化系统设计和开发,正在试图推进以人类易理解的形式实现纳米出版物的发布、检索、浏览、获取与引用.具体来说,Nanobench利用分散式服务网络,帮助用户通过界面交互操作发布小型关联数据语句,同时也为用户查询知识提供了更加便捷且可靠的途径.[34]NanoWeb系统提供了能够访问、探索和重用开放纳米出版物的可视化接口,并支持链接到纳米出版物的出处论文和数据库.[35]纳米出版物引用框架Nanocitation为纳米出版物缺少引用标准提供解决方案,并开发公开可用的WebApp,以便用户自动创建引文文本片段以及机器可读的纳米出版物引用.[36] ...
A Framework for citing nanopublications
1
2019
... 纳米出版物的可视化系统设计和开发,正在试图推进以人类易理解的形式实现纳米出版物的发布、检索、浏览、获取与引用.具体来说,Nanobench利用分散式服务网络,帮助用户通过界面交互操作发布小型关联数据语句,同时也为用户查询知识提供了更加便捷且可靠的途径.[34]NanoWeb系统提供了能够访问、探索和重用开放纳米出版物的可视化接口,并支持链接到纳米出版物的出处论文和数据库.[35]纳米出版物引用框架Nanocitation为纳米出版物缺少引用标准提供解决方案,并开发公开可用的WebApp,以便用户自动创建引文文本片段以及机器可读的纳米出版物引用.[36] ...
Open research knowledge graph:next generation infrastructure for semantic scholarly knowledge
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Analysing the requirements for an open research knowledge graph:use cases,quality requirements,and construction strategies
1
2022
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
The microsoft academic knowledge graph:a linked data source with 8 billion triples of scholarly data
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Oag:toward linking large-scale heterogeneous entity graphs
1
2019
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
AI-KG:An automatically generated knowledge graph of artificial intelligence
1
2020
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
SCICERO:a deep learning and NLP approach for generating scientific knowledge graphs in the computer science domain
1
2022
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
CS-KG:a large-scale knowledge graph of research entities and claims in computer science
1
2022
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
科学论文语义标注框架的设计与应用
1
2020
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
NLPContributions:an annotation scheme for machine reading of scholarly contributions in natural language processing literature
1
2020
... 众包与人机协同的细粒度、大规模知识图谱构建方法得到关注.开放研究知识图谱ORKG融合了众包与自动化技术,被学界视作开放科学背景下语义知识服务的下一代基础设施.[37]目前,有关ORKG的研究仍处于探索阶段,有学者指出这类开放知识图谱需要在迭代和增量中不断改进和评估,注重作者和用户的参与.[38]除ORKG之外,微软学术知识图谱MAG[39],以及大规模异构学术知识图谱OAG[40]等也体现了学界对科学文章内容上知识单元互连的积极探索,其中OAG的2.0版本着重实现了两个大型异构数据集中实体的自动化匹配.学者Dessí和他的团队关注大规模自动生成知识图谱的构建,首次提出AI-KG[41]之后,再次改进知识提取方法提出SCICERO构建方法[42],构建了更大量级、全自动化的CS-KG[43],未来还将允许用户参与构建流程,以实现更细粒度的实体分类.学者们还就语义标注[44,45,46]、知识抽取[47,48]、语义推理与预测[49,50]以及知识图谱构建工作流[51,52]等方向探索优化方案,以提升各类文档资源的语义价值和可用性.这些大规模领域知识图谱的构建为AI for Science(简称AI4S)的发展提供了更多机遇. ...
Scientific discourse tagging for evidence extraction
1
2021
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Mining arguments in scientific abstracts with discourse-level embeddings
1
2020
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Argument mining for scholarly document processing:taking stock and looking ahead
1
2021
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Full-Text argumentation mining on scientific publications
1
2022
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
BAM:benchmarking argument mining on scientific documents
1
2022
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Toward representing research contributions in scholarly knowledge graphs using knowledge graph cells
1
2020
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
Expressing High-Level scientific claims with formal semantics
1
2021
... 基于科技文献构建论证知识图谱也成为新的关注点.具体来说,包括论证话语的论证单元识别[57,58]、论证结构识别[59],以及扩展至文章主体的全文论证挖掘[60]和针对论证挖掘的性能评估方法[61]等多项研究成果涌现.相关学者已经设计出通用的模版来实例化科学论文中的科学论断和学术主张,以构建基于研究贡献的论证知识图谱.[62,63,64] ...
基于本体和关联数据的引文分析方法研究
1
2019
... 引文分析是科学计量学的重要分支.以计算机可理解的方式表示科学论文中的引用关系,可以从引文结构、引用原因、引文网络等多维度进行可溯源的引文计算分析,进而用于科学计量中的学术影响力和知识演变等研究.结合本体和关联数据等语义技术的引文分析方法区别于传统引文分析,具有一定的可操作性,为学者进行科学计量研究提供便利.[65]现阶段语义出版在引文分析上的应用旨在为计量评估开辟新的研究视角,例如聚焦实体以实现更细粒度的引文结构可视化、作者网络自引趋势分析、基于书目实体和引用数据量化书籍在学术交流中的作用[66,67,68]. ...
A semantic representation of the citation structure
1
2019
... 引文分析是科学计量学的重要分支.以计算机可理解的方式表示科学论文中的引用关系,可以从引文结构、引用原因、引文网络等多维度进行可溯源的引文计算分析,进而用于科学计量中的学术影响力和知识演变等研究.结合本体和关联数据等语义技术的引文分析方法区别于传统引文分析,具有一定的可操作性,为学者进行科学计量研究提供便利.[65]现阶段语义出版在引文分析上的应用旨在为计量评估开辟新的研究视角,例如聚焦实体以实现更细粒度的引文结构可视化、作者网络自引趋势分析、基于书目实体和引用数据量化书籍在学术交流中的作用[66,67,68]. ...
The practice of self-citations:a longitudinal study
1
2020
... 引文分析是科学计量学的重要分支.以计算机可理解的方式表示科学论文中的引用关系,可以从引文结构、引用原因、引文网络等多维度进行可溯源的引文计算分析,进而用于科学计量中的学术影响力和知识演变等研究.结合本体和关联数据等语义技术的引文分析方法区别于传统引文分析,具有一定的可操作性,为学者进行科学计量研究提供便利.[65]现阶段语义出版在引文分析上的应用旨在为计量评估开辟新的研究视角,例如聚焦实体以实现更细粒度的引文结构可视化、作者网络自引趋势分析、基于书目实体和引用数据量化书籍在学术交流中的作用[66,67,68]. ...
Nine million book items and eleven million citations:A study of book-based scholarly communication using openCitations
1
2020
... 引文分析是科学计量学的重要分支.以计算机可理解的方式表示科学论文中的引用关系,可以从引文结构、引用原因、引文网络等多维度进行可溯源的引文计算分析,进而用于科学计量中的学术影响力和知识演变等研究.结合本体和关联数据等语义技术的引文分析方法区别于传统引文分析,具有一定的可操作性,为学者进行科学计量研究提供便利.[65]现阶段语义出版在引文分析上的应用旨在为计量评估开辟新的研究视角,例如聚焦实体以实现更细粒度的引文结构可视化、作者网络自引趋势分析、基于书目实体和引用数据量化书籍在学术交流中的作用[66,67,68]. ...
Modeling scientometric indicators using a statistical data ontology
1
2022
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
SEO:a scientific events data model
1
2019
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
DINGO:an ontology for projects and grants linked data
1
2020
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
Extension of the BiDO ontology to represent scientific production
1
2019
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
AI-SPedia:a novel ontology to evaluate the impact of research in the field of artificial intelligence
1
2022
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
ROH:towards a highly usable and flexible knowledge model for the academic and research domains
1
2022
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
Change-Oriented summarization of temporal scholarly document collections by semantic evolution analysis
1
2022
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
Analysing the evolution of computer science events leveraging a scholarly knowledge graph:a scientometrics study of top-ranked events in the past decade
1
2021
... 借助语义技术对科学计量指标进行建模,从文献资源中半自动生成计量指标,也是语义背景下开展科学计量研究的全新方式.[69]首先,从科学论文元数据出发构建本体,能够为科研评估提供更深入的视角,例如科学事件本体SEO[70]、基金项目本体Dingo[71]、重构BiDO以评估科学生产的文献计量数据本体[72],以及兼顾文献计量和替代计量两种数据来源的本体AI-SPedia[73]等.以ROH为代表的本体,对科学交流生命周期中的关键实体与关系进行了建模,包括科研项目、科研学者、学术论文以及研究成果等知识要素.[74]除此之外,还有大型语料库的语义演化分析以及计算机科学领域的科学事件评估与演变探究等.[75,76] ...
几个值得关注的语义出版研究热点
1
2018
... 纳米出版物、微型出版物、知识图谱等以形式化的方式表示知识单元类型及其关系,突出了内容的机器可读性,却忽略了它们作为一种出版物的人类可读性和可交互性.[77]已有少量研究尝试将单个纳米出版物转化为人类可读的HTML页面,但基于大规模语义出版物的知识挖掘和计算过程对用户来说依旧是不透明可见的.未来,面向人类可读的语义出版物阅读工具需要被设计出来,以提高知识对象在动态语义出版过程中的可供性,让用户在使用时能够有效发现新的知识,且有迹可循、有据可依.如此,这种知识服务工具能够提高学术作者、编辑、同行评审人员等角色对语义出版物的理解与应用水平,支撑用户从复杂的互链信息生成见解,进一步实现人类阅读与机器理解的协同作用. ...



{kind=link}
{kind=link}