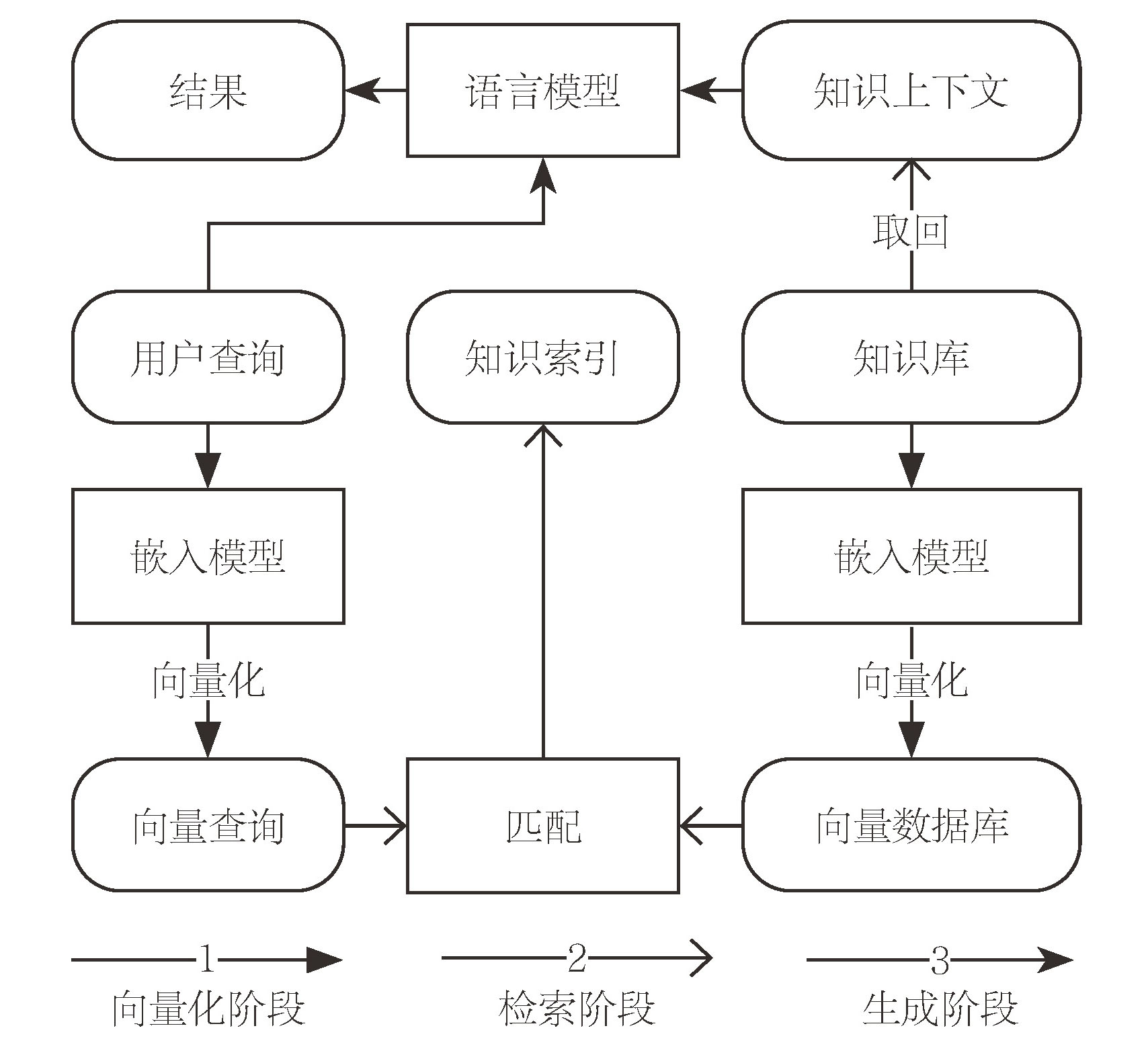
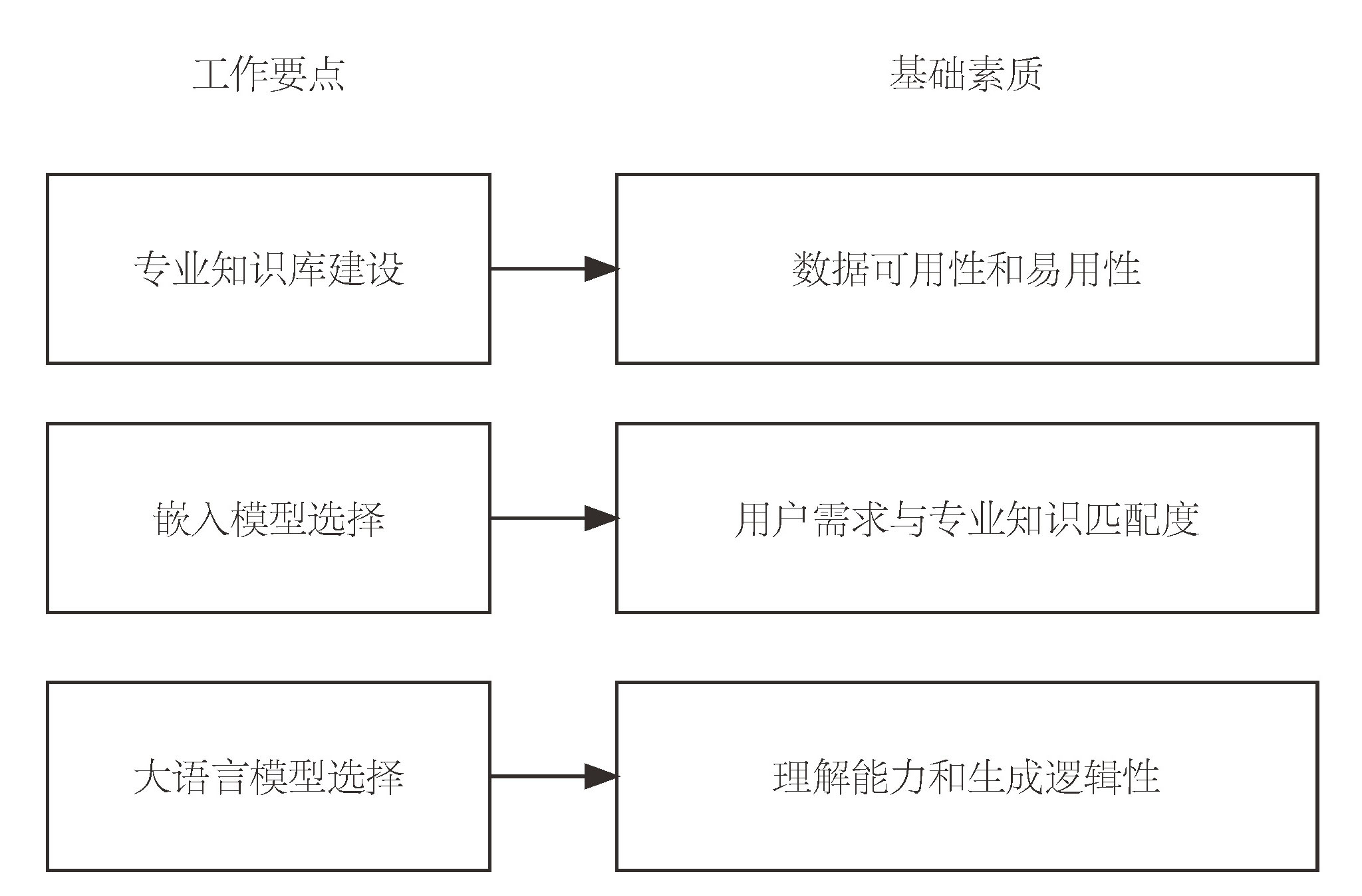
文章从通用人工智能在专业知识服务领域的局限性入手,分析其在语料来源广度与深度、知识迁移泛化与精确性、参数规模与知识覆盖矛盾以及知识时效性与动态性等方面的不足;提出以检索增强生成(RAG)技术为核心的解决方案,通过结合大语言模型的语义理解与生成能力以及专业知识库的权威性与精确性,将检索与生成功能有机结合,平衡知识服务的形式多样性与内容精准性。在此基础上,文章提出基于RAG技术的知识服务系统构建范式、实施路径和效果评估方法,为出版业实施RAG知识服务提供建议。
This paper examines the limitations of artificial general intelligence (AGI) in professional knowledge service domains, particularly its inability to reconcile the breadth of general-purpose corpora with the depth required for specialized expertise, a challenge exacerbated by the static nature of training data and the inherent trade-offs between generalization and precision. These limitations stem from the AGI’s dependence on open-source, nonspecialized training data, which exclude high-value, peer-reviewed resources, and its static architecture, which struggles to adapt to the dynamic evolution of domain knowledge. To address these challenges, this study proposes Retrieval-Augmented Generation (RAG), a hybrid framework that integrates the semantic comprehension and generative fluency of LLMs with the authority and precision of structured knowledge bases. RAG operates through three interconnected phases: vectorization, where domain-specific texts and user queries are transformed into high-dimensional embeddings to capture semantic nuances; retrieval, which employs similarity search algorithms to extract contextually relevant knowledge snippets from vectorized databases, ensuring alignment with professional standards; and generation, where LLMs synthesize retrieved content with user inputs to produce outputs that balance readability with factual accuracy. The implementation of a RAG requires meticulous attention to knowledge base construction, digitization and standardization of domain content through metadata tagging, ontology development, and knowledge graph integration to ensure semantic consistency. Model selection further influences performance: open-source options such as BGE offer flexibility for niche domains but may lack scalability, whereas commercial solutions such as Aliyun’s text embedding provide robust multilingual support at higher costs. LLM selection must align with application needs: models such as DeepSeek-V3 excel in Chinese-language contexts because of localized optimization, whereas GPT-4 proves advantageous for multilingual tasks despite privacy concerns. Experimental validation via simulated datasets—professional technical manuals, educational quizzes, and popular biographies—demonstrated RAG’s efficacy. In professional scenarios, the RAG algorithm achieves excellent accuracy by leveraging structured knowledge bases. However, in educational and popular contexts, accuracy has decreased slightly, but it is still acceptable. For the publishing industry, a RAG offers transformative potential but demands strategic adaptations. Infrastructure localization is paramount for safeguarding proprietary content; hybrid cloud architectures can balance cost efficiency with data security, whereas blockchain integration ensures immutable copyright tracking. Workflow optimization should automate metadata tagging during editorial processes and integrate consistency checks into proofreading stages, reducing manual labor. Data standardization must address multimodal challenges—e.g., aligning image annotations with textual descriptions—to support emerging applications such as interactive textbooks. Copyright protection requires granular access controls and encryption, particularly for subscription-based services. Despite these advancements, the RAG algorithm faces unresolved challenges: multimodal data integration remains computationally intensive, real-time updates strain system latency, and conflicting knowledge sources necessitate advanced conflict-resolution frameworks. Future research should explore adaptive retrieval algorithms, federated learning for decentralized knowledge bases, and hybrid human-AI validation mechanisms to increase reliability. By bridging AGI’s generative capabilities with domain expertise, the RAG not only elevates the precision and adaptability of knowledge services but also catalyzes innovation in digital publishing, enabling industries to harness their authoritative content as dynamic, interactive assets in an increasingly data-driven world.
王亮. 检索增强生成(RAG)驱动的知识服务:原理、范式及评估[J]. 科技与出版, 2025, 44(4): 37-46. WANG Liang. Retrieval-Augmented Generation (RAG)-Driven Knowledge Service: Principles, Paradigms, and Evaluation. Science-Technology & Publication, 2025, 44(4): 37-46.
http://kjycb.tsinghuajournals.com/CN/ 或 http://kjycb.tsinghuajournals.com/CN/Y2025/V44/I4/37
Cited