

同行评议通常由编辑人员之外的领域专家对来稿进行批判性评价 [1],以改进稿件质量并为编辑决策提供依据。严谨的同行评议在保障科学成果的客观、公正及高质量发表传播方面扮演着“科学守门人”的角色,是科技期刊学术质量控制的关键环节 [2-3]。Huber等 [4-5]研究发现,同行评议可能会受到“地位偏差”(马太效应)的影响,即对知名和非知名作者稿件差别对待;性别与区域偏见亦有报道 [6-7]。因此,尽管开放同行评议有助于提升透明度和问责制,但仍面临来自科技期刊、作者与评议专家等层面的诸多挑战 [8]。当前大多数科技期刊仍采用单盲、双盲或二者结合的评审模式,以尽可能地屏蔽作者声望、机构背景、资助来源等非学术因素对评审判断的潜在干扰,从而维护审稿意见的客观性与独立性 [9]。Tomkins等 [10]开展的对照实验表明双盲评审在减少性别、机构及地位偏差方面具有显著效果。操作层面上,单盲要求在向作者反馈意见前隐去审稿专家身份,双盲还需要在送审前对作者相关信息进行充分匿名化。传统主要依赖人工处理,如要求作者额外提交去除姓名、单位的匿名稿或由编辑逐项删除相关敏感信息,流程烦琐、费时费力,还易因细节疏漏而产生隐私泄露风险——如审稿人在Word/PDF文件中的批注与修订记录可能暴露个人信息,除论文首页作者栏外,中英文摘要、基金、致谢、伦理审批、样本来源等版块亦可能间接暴露作者身份。在来稿量持续增长的背景下,单纯依赖人工的脱敏方式已难以同时满足工作效率和隐私保护的双重需求。Office和WPS等办公软件虽有提供一键删除批注人信息等元数据的功能(如通过Office文档检查器)[11],但难以识别中英文作者信息区、摘要、脚注及正文中样本来源、伦理审批号、基金项目号等隐性身份线索,同时只能“一刀切”全部删除,无法提供更细颗粒度的控制,本质上也还要人工逐个处理。
近年来,随着生成式人工智能(Generative AI)和大语言模型(large language model,LLM)的发展,AI在期刊评审、稿件初筛及匿名化环节的应用受到广泛关注。Sabet等 [12]探讨了ChatGPT等AI工具在期刊评审中促进学术公平、减轻语言与地区偏见的潜力,但多数期刊编辑部在将AI融入编辑评估和同行评议流程时仍持观望或谨慎态度,以避免引发数据安全或出版伦理方面的风险。2025年JAMA编辑部发文表示将逐步在同行评议工作中引入AI辅助工具,同时明确人类审稿人对评估和决策负有最终责任 [13]。总体来看,现有探索多集中于利用LLM辅助生成评审意见、优化评审流程等宏观层面,尚缺乏针对同行评议环节敏感信息匿名化的系统研究和可复用技术方案。鉴于此,本文面向科技期刊审稿流程,提出一套“规则+LLM”的作者与审稿人双向隐私智能脱敏策略:以正则规则作基础筛查,同时设计嵌入编辑知识的结构化提示语,引导LLM进行语境判断与精细处理,全面覆盖作者信息、中英文摘要、正文、致谢/基金与伦理说明等内容,以及脚注/尾注、页眉/页脚、批注/修订等区域,对参考文献及学术引用保持原貌,避免误处理。该策略可通过开放API方式嵌入各采编系统,实现送审前自动完成作者信息脱敏,审稿完成后自动完成审稿专家信息脱敏,减少人为疏漏,提升处理效率,为构建更加公正、健康的学术生态提供实践路径。
1 脱敏对象
国内科技期刊投稿论文主流格式为DOC、DOCX格式,少量为WPS、TEX格式。为方便编辑审核,部分还会提供PDF、OFD格式文稿。在双盲审稿流程中,为确保评审的公正性与独立性,期刊编辑必须对稿件进行双向脱敏处理,即同时屏蔽作者与审稿专家的身份信息。
(1)作者信息。针对作者,处理范围不仅包括论文开头部分展示的姓名、单位与联系方式等直接标识,更须深入论文各区域,清除中英文摘要、研究方法中可能暴露样本来源的机构或地区信息,抹去致谢、基金与伦理声明中的具体资助号与审批号,并清除脚注、尾注、页眉、页脚中可能包含的个人简介或机构标识。此外,正文及图表注释中对本机构、设备或项目的暗示性表述也需一并处理。同时,参考文献区段的作者信息主要用于文献追溯和引用统计,一般不作脱敏处理,以避免影响文献准确性。
(2)审稿专家信息。针对审稿专家,脱敏的核心在于消除其评审痕迹与身份线索。这主要涵盖两方面:一是技术层面,须清理在Word、PDF等格式文档中由批注与修订功能自动生成的审稿人姓名,以及文档元数据中记录的创建者和机构信息;二是内容层面,应在向作者返还的评审意见中,隐去审稿人无意间提及的个人学术背景等自我指涉性文字。
2 脱敏策略
本研究构建了科技期刊同行评议双向隐私智能脱敏框架,可分为作者信息脱敏和审稿专家脱敏两大模块,见图 1。
图 1
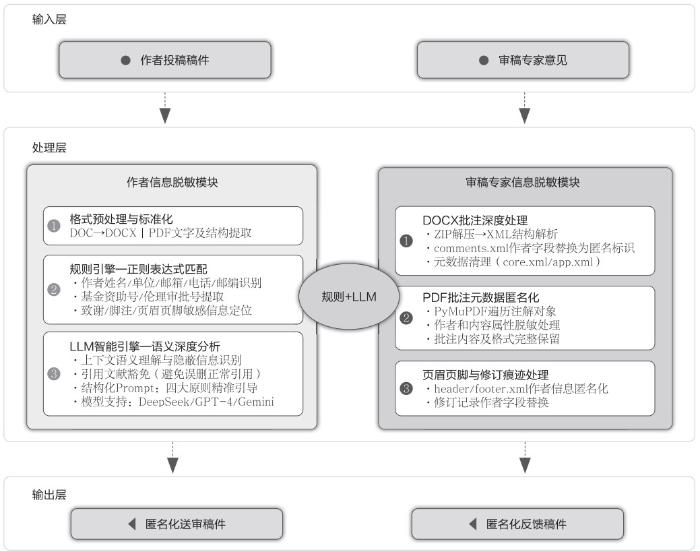
2.1 作者信息智能脱敏
2.1.1 DOC/DOCX格式稿件作者信息脱敏
由于传统的DOC文件采用非结构化存储,通常需要先将其转换为结构化的DOCX文件。DOCX文件本质上是以XML为主体内容的ZIP压缩包,这为程序化解析与信息脱敏提供了便利。
(1)基于模式匹配。正则表达式(regular expression)是一种常用的文本信息提取与替换技术,广泛应用于数据清洗与文本处理任务中,其基本原理是通过预定义的模式规则,在文本中识别符合特定特征的字符串并进行处理。在作者信息脱敏的过程中,正则表达式能够高效识别不同类型的敏感信息,并将其替换为匿名标记,例如“[作者姓名]”“[作者单位]”“[基金信息]”等。程序遍历文档内容,搜索并替换符合预设模式的字符串,从而实现敏感信息的脱敏。其优势在于执行速度快、实现简单,针对特定期刊的固定投稿模板效果尤为显著。然而,这种方法亦存在一定局限性,其高度依赖于规则的定义,缺乏较强的泛化能力,只能识别与预设模式相符的文本。对于非标准格式、未知模式或变异情况(如少数民族姓名或单位名称中的缩写),正则匹配的适用性则较为有限。
(2)基于LLM。针对基于正则表达式的模式匹配方法在泛化能力上的局限性,LLM为敏感信息脱敏提供了更具智能化和适应性的解决方案。与依赖固定模式的正则表达式方法不同,LLM能够深度理解文本的语义信息,并依据上下文语境智能识别敏感作者信息。这种对上下文的感知能力有效克服了正则表达式在处理信息变体和复杂语境时的不足。例如,利用DeepSeek和Gemini等预训练大模型的API,并辅以微调技术,可使其更好地适应科技期刊的特定语料和脱敏需求。这些模型凭借强大的特征提取与语义理解能力,能够区分同一词汇在不同语境下的语义差异。例如,模型能够理解“研究样本来源于中南大学湘雅医院”和“中南大学湘雅医院王教授研究发现”中语境的差异,从而准确判断前者需要脱敏处理,而后者则无须脱敏。此外,结合知识图谱能够进一步提升敏感信息识别和替换的准确性,通过整合期刊、作者、机构、研究领域、基金项目等实体及其相互关系,辅助模型判断特定信息是否需要脱敏。总体而言,基于AI大模型的方法凭借其对文本语义、上下文及实体关系的深度理解,为复杂和多变的脱敏场景提供了比传统正则表达式方法更高效和完善的解决方案。
Polak等 [14]研究表明提示语设计在基于LLM的精准信息提取中起关键作用。为充分发挥LLM的语义识别能力,我们设计了一套结构化提示语,引导模型区别论文中不同部分应用相应脱敏规则。综合期刊编辑实践,我们将Prompt设计归纳为“四大原则”,覆盖了论文各部分常见的敏感信息场景:①强力处理“作者信息块”。这一部分通常位于标题和摘要之间,是身份敏感信息最集中的区域,须严格处理。②完全豁免“文内引用”。文内引用是正文中为了支撑论点引用他人成果的句子,无须匿名处理。③严格脱敏“本文自身”信息。这指正文中描述本研究自身情况的内容,例如样本来源、伦理委员会名称等。④特定模块的精细化策略,针对摘要、致谢、方法、利益冲突等隐私密集部位制定子规则。最后,Prompt中特别注明最终豁免项——文末的参考文献列表不作任何处理,以免影响文献准确性。在构造Prompt时,将上述规则以层次化格式嵌入,使LLM清晰了解不同段落的属性和需采取的操作。通过以上精细设计,实现了结构化Prompt工程:以规则为引导,让LLM在理解上下文的基础上执行准确定制的脱敏操作,有效避免LLM可能出现的随意发挥或内容遗漏,并确保输出格式可以被程序解析验证。
2.1.2 PDF稿件敏感信息预警
PDF稿件因其二进制存储格式和复杂的内部结构,相较于易于编辑的DOC/DOCX文件,在编辑和信息提取方面面临显著的技术挑战。直接修改PDF内容的技术虽然存在,但其操作复杂且容易破坏文档格式。为高效提取PDF文件中的文本信息,通常需要依赖专门的库,例如PyPDF2或PyMuPDF等。部分扫描PDF文件还需要借助光学字符识别(optical character recognition,OCR)技术进行文本转换,这无疑增加了处理流程的复杂性,并可能引入识别误差。因此,针对PDF文件,采用敏感信息预警策略是一种更为稳健且实用的选择。
PDF敏感信息预警的核心在于高效准确地提取文本,并运用文本挖掘技术识别潜在的敏感信息。借鉴基于正则表达式的模式匹配方法,可预设关键词和模式规则对提取的文本进行检索。一旦检测到疑似包含作者敏感信息的文本片段,系统即发出预警,提示编辑人员进行人工复核与处理。该策略的优势在于无需直接修改PDF文件即可保障文档完整性,并能及时发现潜在的隐私泄露风险。
2.2 审稿专家信息智能脱敏
2.2.1 DOC/DOCX专家信息脱敏
对于DOC格式的审稿意见,同样需要先转换为DOCX格式以便处理。DOCX文件中的批注与修订信息是审稿专家身份标识的主要来源,分别存储于comments.xml和document.xml文件中。这些文件中包含了批注者或修订者的身份信息,通常表现为用户名或姓名。通过编程手段操作XML解析库,可以精确定位并修改相关文件中的特定标签和属性,将审稿专家的身份信息替换为预设的匿名标识符,如“本刊编辑”或“审稿人”,从而实现有效脱敏。
2.2.2 PDF稿件专家信息脱敏
对于审稿专家以PDF格式返回的意见,由于PDF文件结构复杂,可以包含文本、图像、矢量图形等多种元素,并且文本的存储方式不尽相同,程序化地定位和修改特定文本信息(如批注者姓名)相对困难。此外,PDF文件的批注信息存储方式也不统一,不同软件生成的PDF文件,其批注信息的存储结构可能存在差异,增加了处理的复杂性。尽管PDF处理存在挑战,借助PyMuPDF可以较为有效地实现PDF稿件中审稿专家信息的脱敏。PyMuPDF库允许程序访问PDF文件的内部结构,提取文本和批注信息。通过分析PDF文件的批注结构,可以定位到包含批注者信息的字段,并进行替换或删除。例如,可以遍历PDF文档的注解(annotations),找到类型为“Comment”的注解,并修改其作者属性。然而,这种方法可能需要针对不同PDF生成软件的输出进行适配,以确保脱敏的准确性和完整性。对于扫描版PDF,则可能需要结合OCR技术先将图像转换为文本,再进行后续的脱敏处理。
3 智能脱敏效果
3.1 DOC/DOCX格式稿件作者信息脱敏效果
传统的处理方式是作者上传两个版本,或者由编辑部手动处理,隐去作者信息。本研究展示了人工智能技术在稿件作者信息脱敏中的测试效果,结果显示,基于正则和ChatGPT大模型对DOC/DOCX格式进行智能脱敏后,稿件的作者名字、单位、基金信息、联系方式、邮箱和邮政编码信息均自动脱敏,见图 2。
图 2a

图 2b

3.2 审稿专家信息智能脱敏
外审专家上传带有修订标记和批注的文档,需要手动把修订标记和批注删掉,再在相同位置重新修订和标注一遍,以免外审专家的姓名(也有用昵称或缩写)被本文作者看到。修订或批注量大的文章,操作起来相当烦琐。唐栋等 [15]探究修改给作者退修稿Word文件里的批注人姓名,此方法虽然达到了脱敏效果,依旧不够智能,经测试单篇平均需要花费3~5分钟,且需要人工操作,很容易因查找操作疏忽,导致脱敏不完全,并且不能批量处理稿件。Office文档检查器虽可一键删除,但也存在之前提到的无法细粒度控制等问题。
图 3

图 4

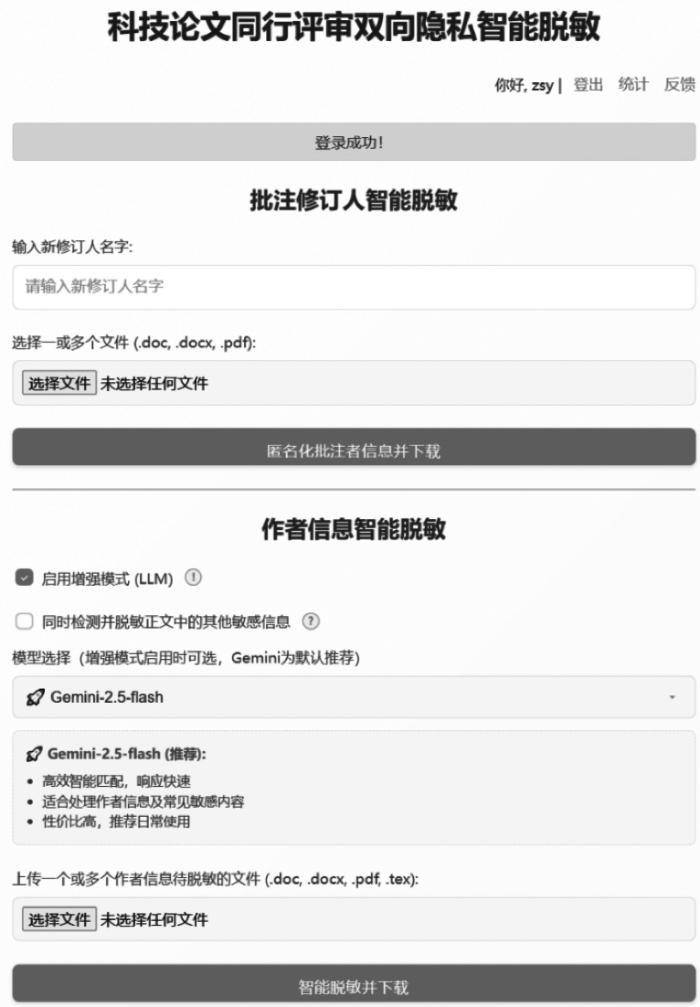
3.3 图形用户界面
为降低编辑人员使用的技术门槛,本研究开发了方便用户直接使用的Web用户界面,见图 5(脱敏系统测试网址:
图 5
4 讨论与分析
4.1 提升隐私保护与公平性
本文提出的“规则+LLM”混合脱敏方案,解决了传统同行评议中人工脱敏效率低和隐私易泄露的痛点,人工、规则、LLM及规则+LLM四种脱敏方式的比较见表 1。从结果看,规则+LLM脱敏策略能够全面清除稿件中可能影响审稿公正性的作者、机构信息,切断了潜在的偏见来源,有助于评审意见回归学术本身。在我国当前推进世界一流科技期刊建设的背景下,评审过程的客观性与评审专家的参与积极性受到高度关注。隐私保护水平的提升有望进一步激发作者和审稿人的参与热情,形成良性循环。
表 1 4种脱敏方案不同维度比较
| 脱敏方案 | 脱敏准确性 | 覆盖范围 | 处理效率 | 一致性 | 风险隐患 | 实现成本 |
| 人工脱敏 | 依赖编辑经验,易有遗漏 | 取决于人工注意力,难涵盖所有细节 | 逐稿人工操作,耗时长,难批量 | 不同编辑标准不一,结果有差异 | 人为疏忽漏删或误删风险高 | 人力投入高 |
| 规则脱敏 | 精确匹配预设模式,高精度,但可能漏掉非常规情况 | 局限于规则库,未知格式难处理 | 机器自动执行,秒级处理单稿件 | 结果稳定一致,但缺乏灵活性 | 规则缺陷致漏脱/误替换,难应对新风险 | 需编写维护规则,开发成本中等 |
| LLM脱敏 | 具备深度语义理解能力,可识别隐性线索,但存在模型幻觉,准确性不可控 | 语种适应性强,但受上下文窗口限制,长文档处理困难,且难以直接解析文档底层结构 | 受网络时延与推理算力限制,全量文本扫描耗时,大批量稿件处理效率低 | 生成式机制具有随机性,同一文本多次处理可能输出不同结果,缺乏标准化质量控制 | 易过度脱敏或误删漏删,依赖外部接口时存在数据外泄与合规风险 | 人力投入较少,但有模型调用成本,私有化部署则面临算力与运维门槛 |
| 规则+LLM混合脱敏 | 语义理解全面,识别隐蔽信息,准确率最高,但对大模型能力有一定要求 | 覆盖范围最广,可区分正文中的文献引用等无须处理的情况 | 自动批量处理,整体高效,处理全文耗时处于规则和LLM之间 | 基于统一规则和模型,输出更加稳定可控 | 遗漏或误处理风险最低,需注意AIGC伦理及法规要求 | 模块较复杂,调用LLM有一定经济成本,但可大幅降低人力成本 |
4.2 规则+LLM混合策略有效性
单纯依赖人工或固定规则均难以兼顾效率和准确性,而将模式匹配与AI大语言模型结合能够达到“1+1>2”的效果。正则规则提供了清晰的边界和高精度基础,LLM则补充了语义理解的“长尾”能力,使系统对各种复杂上下文均有较强适应性。特别之处在于,我们设计的结构化提示语将领域规则融入模型提示,提高了模型输出的可控性和可信度。
4.3 系统集成与应用前景
目前脱敏服务主要通过浏览器/服务器架构的应用系统完成,未来可提供标准化的API接口,将脱敏模块可作为独立服务嵌入不同编辑平台。这种松耦合方式意味着各期刊社无须大改现有系统,即可享受到智能双向脱敏功能,同时省掉当前的上传下载流程。还可进一步开发Word/WPS插件及浏览器扩展,使编辑和审稿人在本地文档环境中直接调用脱敏功能。除了传统期刊双盲审稿流程,本研究提出的脱敏引擎还可扩展至学术会议论文评审、科研项目评审、学位论文匿名评阅、人才评审材料、教学案例库构建等多种场景。值得强调的是,技术的进步必须辅以完善的管理制度才能真正发挥作用。隐私脱敏策略的实施需要建立配套的规章,如将脱敏步骤纳入审稿流程规范,明确责任人和审核要求,定期检查系统日志以发现异常。只有技术与制度双管齐下,才能构建可靠的隐私保护屏障。
5 结语
面向科技期刊同行评议的“双盲”场景,本文提出并实践了“规则+LLM”双核驱动的双向隐私智能脱敏策略,在不改变稿件内容与版式的前提下,实现对作者与审稿人敏感信息的自动化处理,提升评审公正性与编辑工作效率。该策略可通过标准化接口嵌入采编系统的送审与反馈关键节点,形成匿名化处理闭环,减少人工干预与纰漏,并保持参考文献与学术引用的原貌。本研究的初衷是为提升同行评审公平与效率开展技术路径探索,主要适用于对匿名性要求最高的双盲评审,也可用于单盲评审中审稿专家敏感信息脱敏;对于强调身份透明的开放式同行评议则不适用。当然,本方案在实践中也面临新的挑战,一方面是模型API的调用成本与时延,以及外部数据处理的安全合规问题,有条件的编辑部可考虑采用本地统一部署大模型服务或企业级可信API,由本地规则引擎处理大部分姓名、单位等显性信息,仅将难以判断的语义片段经特征化后发送给LLM辅助判断,以尽量降低外传风险;另一方面,正如Bauersfeld等 [16]的研究所示,任何技术匿名手段都存在被更高阶人工智能技术破解的风险。未来将持续完善规则库与结构化提示语,将技术手段与编辑规范、伦理审查和管理制度相结合,强化日志审计与权限控制,在促进学术开放交流的同时守住隐私底线,推动学术生态向更加公平、高效、可信的方向发展。
参考文献
Nobel and novice:Author prominence affects peer review
[J].
The present and future of peer review:Ideas,interventions,and evidence
[J].
Gender bias in scholarly peer review
[J].
The impact of double-blind peer review on gender bias in scientific publishing:a systematic review
[J].
Reviewer bias in single-versus double-blind peer review
[J].DOI:10.1073/pnas.1707323114 [本文引用: 1]
Equity in scientific publishing:Can artificial intelligence transform the peer review process?
[J].DOI:10.1016/j.mcpdig.2023.10.002 [本文引用: 1]
Artificial intelligence in peer review
[J].
Extracting accurate materials data from research papers with conversational language models and prompt engineering
[J].
Cracking double-blind review:Authorship attribution with deep learning
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}